
Intel Core i7-3770K et i5-3570K : Ivy Bridge 22nm en test
Publié le 23/04/2012 par Guillaume Louel et Marc Prieur



Tick oblige, dans les grades lignes, l'architecture d'Ivy Bridge reprend celle de son prédécesseur à savoir Sandy Bridge. Nous vous renvoyons donc à notre article précédent pour les détails. Nous allons nous concentrer aujourd'hui principalement sur les différences et les nouveautés apportés par Ivy Bridge par rapport à son prédécesseur.
Vu de haut, les choix techniques effectués par Intel pour Sandy Bridge sont confirmés dans Ivy Bridge. La première était l'intégration de ce que l'on appelait historiquement northbridge dans les cartes mères, la partie du chipset qui contenait les contrôleurs mémoires, PCI Express et éventuellement IGP.
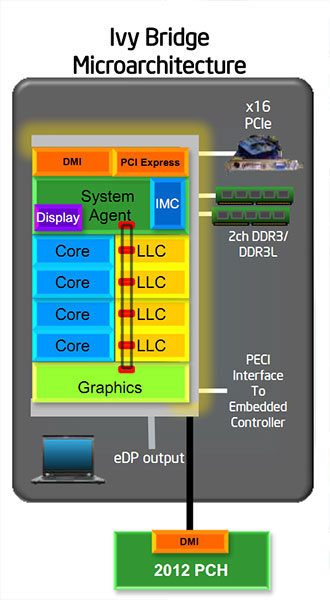
Intel implémente cela dans Ivy Bridge sous la forme d'un die unique intégrant tout d'abord deux ou quatre curs selon le modèle de die, un cache de niveau 3 baptisé LLC pouvant aller jusqu'à 8 Mo, un cur graphique, et la partie uncore qui regroupe le contrôleur mémoire DDR3, la gestion des écrans, le lien vers le southbridge (via un bus DMI, qui est l'équivalent d'un bus PCIe x4), ainsi que le contrôleur PCI Express x16. Tous ces blocs fonctionnels sont reliés par un bus interne de type ring bus qui permet par exemple le partage du LLC entre les cores x86 et le cur graphique.
A l'intérieur des curs, on notera assez peu de changements. Pas de nouveau jeu de fonctionnalité complet à l'image d'AVX dans Sandy Bridge (AVX2 arrivera avec Haswell l'an prochain) mais l'on retrouve tout de même quelques petits changements.
Intel ajoute quelques instructions d'abord pour convertir rapidement des données de type flottantes 32 bits simple précision vers un format Float16 compressé (1 bit de signe, 5 bits d'exposant, 10 bits significatifs). Ces instructions (VCVTPH2PS et VCVTPS2PH) sont disponibles dans des variantes vectorielles SSE/AVX 128 et 256 bits. On notera également de manière plus anecdotique de nouvelles instructions qui permettent de lire les segments FS/GS, ces derniers étant d'habitude plutôt réservés au système d'exploitation.
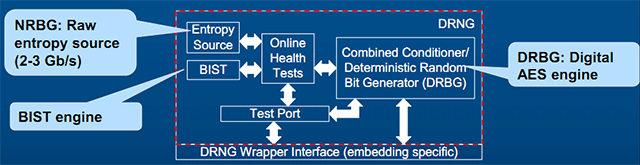
On trouvera par contre un générateur de nombres aléatoires numériques. On parle de générateur numérique car la puce intègre une source d'entropie (la partie purement aléatoire, que certains outils de cryptage simulent à la génération des clefs en vous demandant de bouger la souris dans tous les sens). Ici, Intel indique un débit de 2 à 3 Gb/s ce qui devrait offrir des performances intéressantes pour les applications qui le requiert. Le tout est englobé dans un bloc fonctionnel auquel on accède par une instruction (RDRAND) qui pourra ainsi fournir à la demande un nombre aléatoire (conforme ANSI X9.82, NIST SP800-90 et NIST FIPS 140-2/3 niveau 2) 16, 32 ou 64 bits.
On notera enfin comme dernier changement au niveau du jeu d'instruction une modification des opérations de déplacement/remplissage de blocs mémoires. Il ne s'agit pas ici de nouvelles instructions, mais de l'optimisation des instructions REP MOVSB et REP STOSB dont la rapidité a été optimisée pour des blocs de plus de 64 octets. Intel indique ainsi vouloir supprimer les algorithmes spécifiques à chaque processeur que l'on retrouve dans les bibliothèques utilisées par les compilateurs ou les runtime. Un pas en avant intéressant pour l'avenir (ces algorithmes optimisés par processeur le sont souvent de manière partielle, créant des écarts de performances qui pourraient être évités, nous vous renvoyons à notre dossier sur le sujet) s'il est suivi dans la durée, et si AMD embraye également sur cette voie. Les REP MOVSB/STOSB n'étant pas jusqu'ici la manière privilégiée pour ces opérations sur les processeurs K10 et suivants.
En sus de ces changements dans l'ISA proprement dite, Intel a également effectué quelques petites optimisations dans le pipeline pour améliorer l'IPC. Ainsi Intel a amélioré la performance de ses instructions de divisions et rajouté des améliorations pour détecter et supprimer des MOV inutiles. Certaines modifications qui jouent sur l'IPC ne sont cependant pas forcément incluses directement dans le pipeline mais directement dans l'uncore.
En ce qui concerne la latence, nous avons noté un progrès aussi bien au niveau du cache LLC que de la mémoire. Ainsi à 4.5 GHz nous avons noté 4.3ns pour Sandy Bridge contre 3.4 pour Ivy Bridge.
Côté mémoire, avec de la mémoire DDR3-1600 9-9-9 la latence mesurée via AIDA64 diminue de 45.1ns à 39.3ns.
Outre sa vitesse, le LLC évolue également dans son modèle de remplissage, retravaillé. Baptisé Adaptative Fill Policy, elle joue plus particulièrement sur la manière dont IGP et codes x86 se partagent cette ressource commune qu'est le LLC. Intel dit avoir travaillé sur la base d'heuristiques récupérées via Sandy Bridge pour optimiser le fonctionnement d'Ivy Bridge. Cela pourrait limiter les effets de collisions que nous avions pu noter au lancement de Sandy Bridge lorsque l'on utilise en simultanée une application qui stresse les cores x86 et l'IGP. Nous vérifierons cela en pratique.
L'algorithme LRU qui permet de dater l'ancienneté des données présentes dans le cache devient un peu plus flexible en passant sur deux bits pour améliorer la granularité. L'unité de prefetch mémoire dispose également désormais mécanisme de throttling qui permet de limiter son agressivité lorsque les accès mémoires sont déjà trop nombreux. Pour cela, ce mécanisme se base sur la bande passante mémoire en temps réel actuellement utilisée.
On notera enfin deux changements additionnels dans l'uncore. Le premier concerne la gestion d'un power gating au niveau du processeur pour la tension VccP utilisée pour les I/O DDR. Cette dernière est réduite dans les C-states les plus élevés (C3 package et supérieurs). Intel espère ainsi obtenir 100mW d'économie d'énergie lorsque la machine est au repos, ce qui peut être intéressant sur les plateformes portables. Au niveau du contrôleur mémoire Intel ajoute deux changements, le premier étant la gestion de la DDR3 basse tension sur les versions mobiles d'Ivy Bridge, la seconde étant un support "officiel" de la mémoire DDR3-1600 avec deux barrettes mémoires par canal. Pour rappel nous avons utilisé dans notre dernier comparatif de cartes mères quatre barrettes DDR3 2133 avec un processeur Sandy Bridge sans aucun problème.
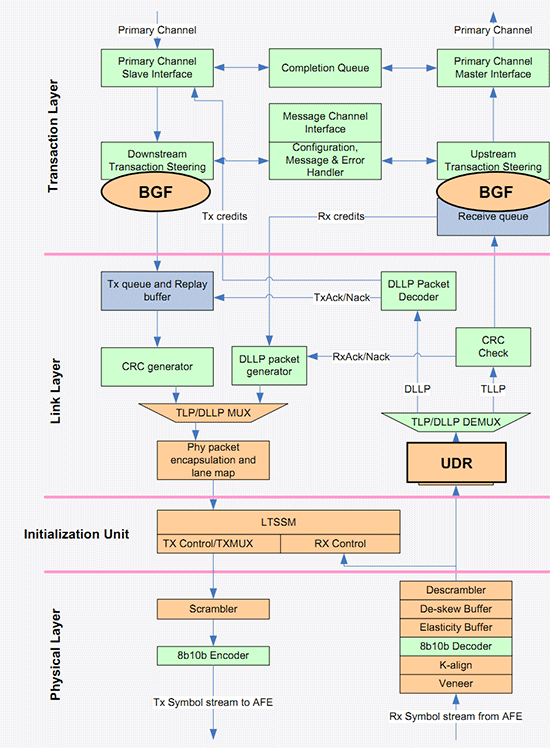
En orange, les modifications effectuées au contrôleur original (vert). Les modifications en bleu indiquent les changement des buffers
La dernière modification concerne la gestion du PCI Express 3.0 qui a été ajoutée. Contrairement à ce que l'on pourrait penser, elle ne reprend pas l'implémentation utilisée par Intel pour SNB-E (la plateforme X79), il s'agit d'une implémentation distincte qui se base sur celle originale de Sandy Bridge. Seuls les buffers développés pour SNB-E ont été repris dans la nouvelle implémentation qui, selon les ingénieurs d'Intel, doit améliorer significativement les performances par rapport à la plateforme SNB-E en PCI Express 3.0. Les performances brutes que nous avions relevées à l'époque n'étaient pour rappel pas exceptionnelles.
Au rang des changements originaux, on notera l'arrivée de TDP variables pour les machines mobiles. En plus d'une version nominale, deux modes de fonctionnements distincts, baptisés TDP down et TDP up ont été intégrés. Le premier pourra par exemple être activé uniquement lorsque la machine est branchée sur secteur tandis que le dernier représenterait un mode d'économie d'énergie maximale. L'implémentation n'est que très peu détaillée par Intel et semble avant tout là pour donner un peu plus de flexibilité derrière Speedstep qui était utilisé jusque là pour cela. L'implémentation des modes TDP up/down sera à la discrétion des intégrateurs, il faudra attendre l'arrivée des versions mobiles d'Ivy Bridge pour en savoir plus.
 22 nm et Tri-gate
Les améliorations côté GPU
22 nm et Tri-gate
Les améliorations côté GPU

De nombreux points communs
Vu de haut, les choix techniques effectués par Intel pour Sandy Bridge sont confirmés dans Ivy Bridge. La première était l'intégration de ce que l'on appelait historiquement northbridge dans les cartes mères, la partie du chipset qui contenait les contrôleurs mémoires, PCI Express et éventuellement IGP.
Intel implémente cela dans Ivy Bridge sous la forme d'un die unique intégrant tout d'abord deux ou quatre curs selon le modèle de die, un cache de niveau 3 baptisé LLC pouvant aller jusqu'à 8 Mo, un cur graphique, et la partie uncore qui regroupe le contrôleur mémoire DDR3, la gestion des écrans, le lien vers le southbridge (via un bus DMI, qui est l'équivalent d'un bus PCIe x4), ainsi que le contrôleur PCI Express x16. Tous ces blocs fonctionnels sont reliés par un bus interne de type ring bus qui permet par exemple le partage du LLC entre les cores x86 et le cur graphique.
Améliorations de l'ISA
A l'intérieur des curs, on notera assez peu de changements. Pas de nouveau jeu de fonctionnalité complet à l'image d'AVX dans Sandy Bridge (AVX2 arrivera avec Haswell l'an prochain) mais l'on retrouve tout de même quelques petits changements.
Intel ajoute quelques instructions d'abord pour convertir rapidement des données de type flottantes 32 bits simple précision vers un format Float16 compressé (1 bit de signe, 5 bits d'exposant, 10 bits significatifs). Ces instructions (VCVTPH2PS et VCVTPS2PH) sont disponibles dans des variantes vectorielles SSE/AVX 128 et 256 bits. On notera également de manière plus anecdotique de nouvelles instructions qui permettent de lire les segments FS/GS, ces derniers étant d'habitude plutôt réservés au système d'exploitation.
On trouvera par contre un générateur de nombres aléatoires numériques. On parle de générateur numérique car la puce intègre une source d'entropie (la partie purement aléatoire, que certains outils de cryptage simulent à la génération des clefs en vous demandant de bouger la souris dans tous les sens). Ici, Intel indique un débit de 2 à 3 Gb/s ce qui devrait offrir des performances intéressantes pour les applications qui le requiert. Le tout est englobé dans un bloc fonctionnel auquel on accède par une instruction (RDRAND) qui pourra ainsi fournir à la demande un nombre aléatoire (conforme ANSI X9.82, NIST SP800-90 et NIST FIPS 140-2/3 niveau 2) 16, 32 ou 64 bits.
On notera enfin comme dernier changement au niveau du jeu d'instruction une modification des opérations de déplacement/remplissage de blocs mémoires. Il ne s'agit pas ici de nouvelles instructions, mais de l'optimisation des instructions REP MOVSB et REP STOSB dont la rapidité a été optimisée pour des blocs de plus de 64 octets. Intel indique ainsi vouloir supprimer les algorithmes spécifiques à chaque processeur que l'on retrouve dans les bibliothèques utilisées par les compilateurs ou les runtime. Un pas en avant intéressant pour l'avenir (ces algorithmes optimisés par processeur le sont souvent de manière partielle, créant des écarts de performances qui pourraient être évités, nous vous renvoyons à notre dossier sur le sujet) s'il est suivi dans la durée, et si AMD embraye également sur cette voie. Les REP MOVSB/STOSB n'étant pas jusqu'ici la manière privilégiée pour ces opérations sur les processeurs K10 et suivants.
En sus de ces changements dans l'ISA proprement dite, Intel a également effectué quelques petites optimisations dans le pipeline pour améliorer l'IPC. Ainsi Intel a amélioré la performance de ses instructions de divisions et rajouté des améliorations pour détecter et supprimer des MOV inutiles. Certaines modifications qui jouent sur l'IPC ne sont cependant pas forcément incluses directement dans le pipeline mais directement dans l'uncore.
Améliorations de l'uncore
En ce qui concerne la latence, nous avons noté un progrès aussi bien au niveau du cache LLC que de la mémoire. Ainsi à 4.5 GHz nous avons noté 4.3ns pour Sandy Bridge contre 3.4 pour Ivy Bridge.
Côté mémoire, avec de la mémoire DDR3-1600 9-9-9 la latence mesurée via AIDA64 diminue de 45.1ns à 39.3ns.
Outre sa vitesse, le LLC évolue également dans son modèle de remplissage, retravaillé. Baptisé Adaptative Fill Policy, elle joue plus particulièrement sur la manière dont IGP et codes x86 se partagent cette ressource commune qu'est le LLC. Intel dit avoir travaillé sur la base d'heuristiques récupérées via Sandy Bridge pour optimiser le fonctionnement d'Ivy Bridge. Cela pourrait limiter les effets de collisions que nous avions pu noter au lancement de Sandy Bridge lorsque l'on utilise en simultanée une application qui stresse les cores x86 et l'IGP. Nous vérifierons cela en pratique.
L'algorithme LRU qui permet de dater l'ancienneté des données présentes dans le cache devient un peu plus flexible en passant sur deux bits pour améliorer la granularité. L'unité de prefetch mémoire dispose également désormais mécanisme de throttling qui permet de limiter son agressivité lorsque les accès mémoires sont déjà trop nombreux. Pour cela, ce mécanisme se base sur la bande passante mémoire en temps réel actuellement utilisée.
On notera enfin deux changements additionnels dans l'uncore. Le premier concerne la gestion d'un power gating au niveau du processeur pour la tension VccP utilisée pour les I/O DDR. Cette dernière est réduite dans les C-states les plus élevés (C3 package et supérieurs). Intel espère ainsi obtenir 100mW d'économie d'énergie lorsque la machine est au repos, ce qui peut être intéressant sur les plateformes portables. Au niveau du contrôleur mémoire Intel ajoute deux changements, le premier étant la gestion de la DDR3 basse tension sur les versions mobiles d'Ivy Bridge, la seconde étant un support "officiel" de la mémoire DDR3-1600 avec deux barrettes mémoires par canal. Pour rappel nous avons utilisé dans notre dernier comparatif de cartes mères quatre barrettes DDR3 2133 avec un processeur Sandy Bridge sans aucun problème.
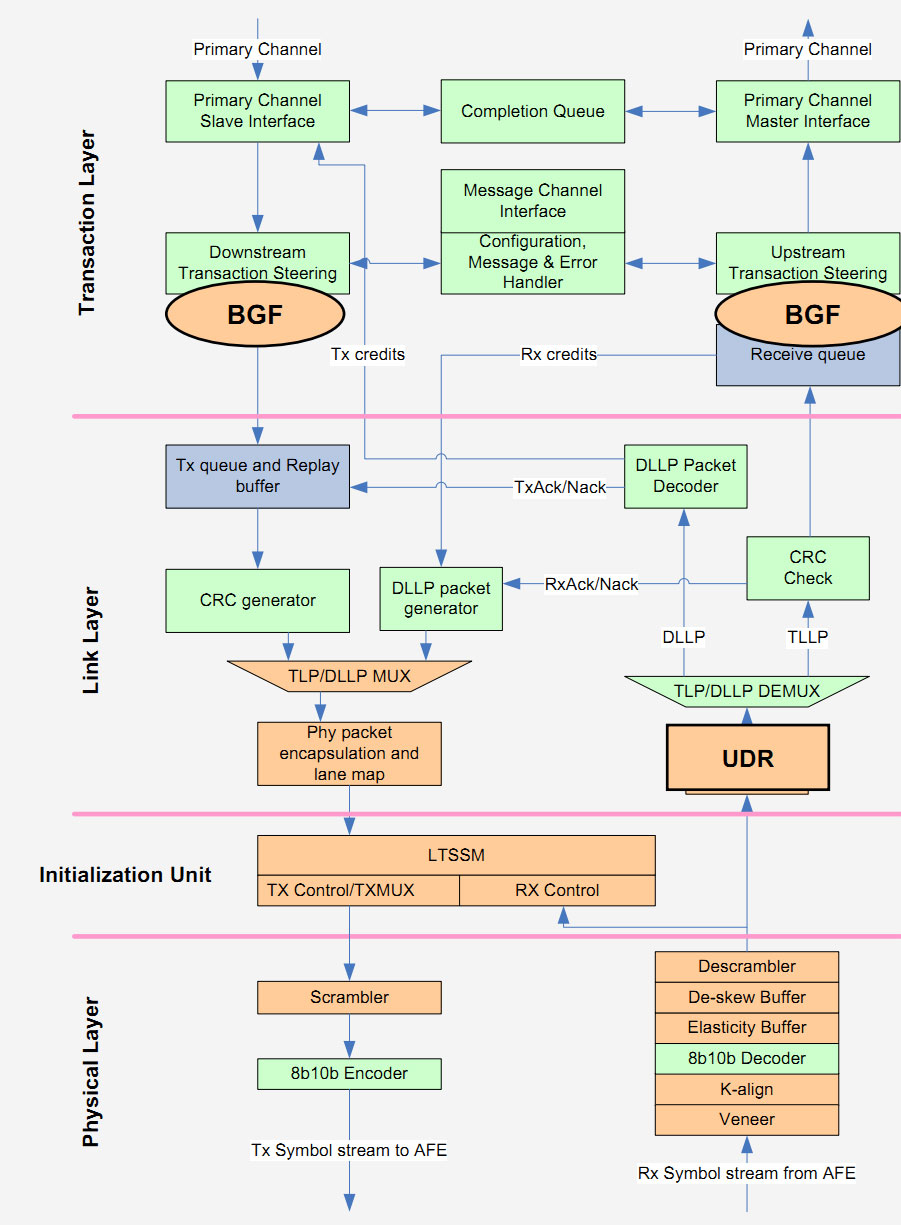
En orange, les modifications effectuées au contrôleur original (vert). Les modifications en bleu indiquent les changement des buffers
La dernière modification concerne la gestion du PCI Express 3.0 qui a été ajoutée. Contrairement à ce que l'on pourrait penser, elle ne reprend pas l'implémentation utilisée par Intel pour SNB-E (la plateforme X79), il s'agit d'une implémentation distincte qui se base sur celle originale de Sandy Bridge. Seuls les buffers développés pour SNB-E ont été repris dans la nouvelle implémentation qui, selon les ingénieurs d'Intel, doit améliorer significativement les performances par rapport à la plateforme SNB-E en PCI Express 3.0. Les performances brutes que nous avions relevées à l'époque n'étaient pour rappel pas exceptionnelles.
TDP Variable sur les versions mobiles
Au rang des changements originaux, on notera l'arrivée de TDP variables pour les machines mobiles. En plus d'une version nominale, deux modes de fonctionnements distincts, baptisés TDP down et TDP up ont été intégrés. Le premier pourra par exemple être activé uniquement lorsque la machine est branchée sur secteur tandis que le dernier représenterait un mode d'économie d'énergie maximale. L'implémentation n'est que très peu détaillée par Intel et semble avant tout là pour donner un peu plus de flexibilité derrière Speedstep qui était utilisé jusque là pour cela. L'implémentation des modes TDP up/down sera à la discrétion des intégrateurs, il faudra attendre l'arrivée des versions mobiles d'Ivy Bridge pour en savoir plus.
Sommaire
1 - La tactique du Tick - Tock
2 - 22 nm et Tri-gate
3 - Les améliorations côté CPU
4 - Les améliorations côté GPU
5 - Gamme et plate-forme Ivy Bridge
6 - HD Graphics 4000 et 2500 : consommation et 3D
7 - HD Graphics : CPU vs IGP, QuickSync
8 - Core i5-3570K et 3770K, DZ77GA-70K et protocole
9 - Consommation, efficacité énergétique
10 - Température
11 - Overclocking et undervolting
12 - Performances à fréquence égale, DDR3-2133, PCI-Express 3.0
2 - 22 nm et Tri-gate
3 - Les améliorations côté CPU
4 - Les améliorations côté GPU
5 - Gamme et plate-forme Ivy Bridge
6 - HD Graphics 4000 et 2500 : consommation et 3D
7 - HD Graphics : CPU vs IGP, QuickSync
8 - Core i5-3570K et 3770K, DZ77GA-70K et protocole
9 - Consommation, efficacité énergétique
10 - Température
11 - Overclocking et undervolting
12 - Performances à fréquence égale, DDR3-2133, PCI-Express 3.0
13 - Rendu 3D : Mental Ray et V-Ray
14 - Compilation : Visual Studio et MinGW/GCC
15 - Compression : 7-zip et WinRAR
16 - Encodage : x264 et MainConcept H.264
17 - Traitement photo : Lightroom et Bibble
18 - IA d'échecs : Houdini et Fritz
19 - Jeux 3D : Crysis 2 et Arma II : OA
20 - Jeux 3D : Rise of Flight et F1 2011
21 - Jeux 3D : Total War Shogun 2, Starcraft II et Anno 1404
22 - Moyennes
23 - Conclusion
14 - Compilation : Visual Studio et MinGW/GCC
15 - Compression : 7-zip et WinRAR
16 - Encodage : x264 et MainConcept H.264
17 - Traitement photo : Lightroom et Bibble
18 - IA d'échecs : Houdini et Fritz
19 - Jeux 3D : Crysis 2 et Arma II : OA
20 - Jeux 3D : Rise of Flight et F1 2011
21 - Jeux 3D : Total War Shogun 2, Starcraft II et Anno 1404
22 - Moyennes
23 - Conclusion
Vos réactions
Contenus relatifs
- [+] 09/05: AMD Ryzen 7 2700, Ryzen 5 2600 et I...
- [+] 05/04: Pas de MAJ Microcode pour les Gulft...
- [+] 03/04: Intel lance la 2ème vague de sa 8èm...
- [+] 05/10: Intel Core i7-8700K, Core i5-8600K,...
- [+] 12/09: Core i7-7820X : Un Skylake-X mieux ...
- [+] 07/09: Les Skylake en fin de vie chez Inte...
- [+] 23/08: Coffee Lake incompatible avec les L...
- [+] 29/06: Intel Core i9-7900X et Core i7-7740...
- [+] 03/01: Core i5-7600K et i7-7700K : pour qu...
- [+] 28/12: Gigabyte BRIX Gaming GT