
Nvidia GeForce GTX 1080, le premier GPU 16nm en test !



GP104 : 7.2 milliards de transistors en 16 nm
Pour l'introduction de sa nouvelle architecture Pascal auprès des joueurs, Nvidia reprend la même approche que lors du lancement de la génération Maxwell. Le premier GPU à intégrer la famille GeForce est ainsi une puce de taille moyenne : le GP104. Après le GP100 dédié aux accélérateurs Tesla, il s'agit de la seconde puce Nvidia produite par TSMC sur le procédé de fabrication 16 nm FinFET Plus. (FF+).
Après plus de 4 ans de GPU fabriqués en 28 nm chez le même TSMC, le passage au 16 nm FF+ représente une évolution significative qui permet de nouveaux compromis plus avantageux en termes de consommation énergétique, de performances et de fonctionnalités. Les choix de Nvidia pour ce GP104 peuvent se résumer en deux points : hautes fréquences et optimisations orientées vers la réalité virtuelle.
 Le GP104 et sa mémoire GDDR5X.
Le GP104 et sa mémoire GDDR5X.Avant de rentrer dans les détails de son architecture, un petit rappel s'impose pour situer le GP104 parmi les GPU récents :
- GP100 : 15.3 milliards de transistors pour 610 mm²
- Fiji : 8.9 milliards de transistors pour 598 mm²
- GM200 : 8.0 milliards de transistors pour 601 mm²
- GP104 : 7.2 milliards de transistors pour 314 mm²
- GK110 : 7.1 milliards de transistors pour 561 mm²
- Hawaii : 6.2 milliards de transistors pour 438 mm²
- GM204 : 5.2 milliards de transistors pour 398 mm²
- Tonga : 5.0 milliards de transistors pour 368 mm²
- GK104 : 3.5 milliards de transistors pour 294 mm²
La taille maximale que les outils de productions actuels autorisent tourne autour des 600 mm², raison pour laquelle elle correspond aux plus gros GPU tels que le GP100. Avec 314 mm², le GP104 est donc bien un GPU de taille moyenne qui s'inscrit directement dans la lignée des GK104 (GTX 680) et GM204 (GTX 980). Comme nous allons le voir, un GPU de ce calibre en 16 nm exploite la même enveloppe thermique que le GM204 (180 W), ce qui laisse de la place pour un plus gros GPU basé sur les mêmes technologies mais destiné à une enveloppe thermique de 250W des GeForce GTX x80 Ti ou GTX Titan. Ce sera à priori un GPU différent du GP100, peut-être un futur GP102.
Le passage au 16 nm permet évidemment de faire exploser la densité de transistors par rapport au 28 nm. Il ne faut cependant pas se fier à ces chiffres qui sont plus des noms commerciaux des procédés de fabrication que des mesures de la géométrie qui définissent leur densité. Ainsi, contrairement à ce qui a pu être vrai par le passé, le 16 nm ne permet pas de tripler le nombre de transistors par mm² par rapport au 28 nm. Ces technologies sont très complexes et la densité réelle est déterminée par de nombreux paramètres qui dépassent le cadre de cet article. Voici les densités relevées sur les GPU Nvidia les plus récents :
- GP100 : 25.1 millions de transistors par mm²
- GM200 : 13.3 millions de transistors par mm²
- GP104 : 22.9 millions de transistors par mm²
- GM204 : 13.1 millions de transistors par mm²
La densité est un petit peu plus élevée sur les plus gros GPU, probablement parce qu'une partie des E/S (entrées/sorties, I/O) à faible densité est identique et représente moins d'espace en proportion alors qu'à l'inverse ils intègrent en général plus de mémoire qui représente des structures plus denses. Entre le GP104 et le GM204, la densité progresse d'environ 75%. Mais cela ne veut pas dire que le GP104 embarque 75% de transistors en plus. Probablement en partie pour faire face aux coûts de production par wafer, et donc par mm², qui sont en hausse sur le 16 nm, Nvidia n'exploite à peu près que la moitié de ce gain potentiel de transistors et se contente d'une puce 20% plus petite.
GP104 : SM, Pascal G et Pascal T
Pour comprendre l'architecture du GP104, quelques rappels s'imposent concernant la manière dont Nvidia schématise l'organisation interne de ses GPU. A un niveau élevé, ils se composent de un ou plusieurs GPC (Graphics Processing Cluster). Chacun contient un rasterizer chargé de projeter les primitives et de le découper en pixels.
A l'intérieur de ces GPC, nous retrouvons un ou plusieurs TPC (Texture Processor Cluster). Ne vous fiez pas à ce nom, vestige de précédentes architectures, le TPC est aujourd'hui décrit comme la structure qui représente le Polymorph Engine, nom donné à l'ensemble des petites unités fixes dédiées au traitement de la géométrie (chargement des vertices, tessellation etc.).
Enfin, au plus bas niveau, ces TPC intègrent un ou plusieurs SM (Streaming Multiprocessor) qui représentent le coeur de l'architecture. C'est à leur niveau que prennent place les unités de calcul, les unités de texturing, les registres ou encore la mémoire partagée utile au GPU computing.
A noter que pour les GPU Kepler et Maxwell, Nvidia a mis de côté le TPC pour simplifier leur représentation schématique. Un seul SM est présent par TPC pour l'ensemble de ces GPU, il n'y avait donc pas de raison de faire une distinction entre ces deux structures.
A l'intérieur d'un SM Maxwell ou Pascal, nous retrouvons une mémoire partagée (contrôlée par le développeur) et plusieurs partitions organisées en paires. Chaque partition contient entre autres sa propre logique d'ordonnancement, ses registres, une unité 32-bit vectorielle 32-way pour les instructions simples (qui représente 32 cores en termes marketing) et une unité SFU vectorielle 8-way pour certaines instructions complexes. Chaque paire de partitions partage 4 unités de texturing et un cache L1 de 24 Ko.
Pour représenter les différents SM, nous avons modifié des diagrammes de Nvidia de façon à nous rapprocher de la réalité, au mieux de nos connaissances actuelles des différentes architectures :
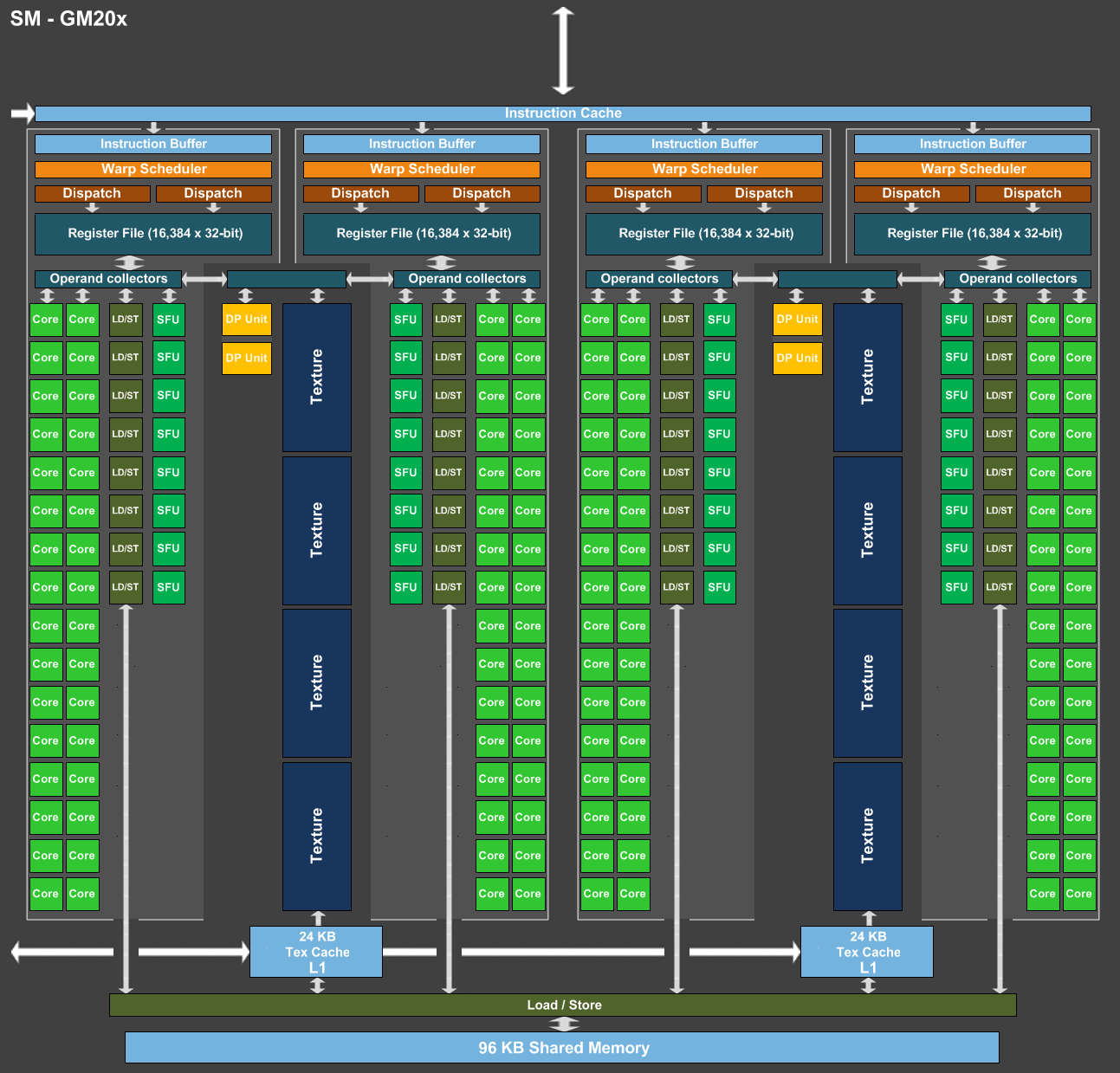
[ SM - GM20x ] [ SM - GP104 ] [ SM - GP100 ]
Comment se compare le SM de Pascal au SM de Maxwell ? Une question à laquelle il est à la fois simple et complexe de répondre puisque nous avons en fait affaire à 2 architectures Pascal différentes que nous qualifierons, en l'absence de mieux, de Pascal G comme GeForce dans le cas du GP104 et de Pascal T comme Tesla dans le cas du GP100.
Pour Pascal G, c'est simple, le SM est fonctionnellement identique à celui des GPU Maxwell 2 (GM20x). Lorsque Nvidia a dévoilé l'architecture Pascal et le GP100, nous avons par contre pu découvrir une refonte importante du SM : il voit sa taille divisée par deux mais gagne de nombreuses unités de calcul en double précision (FP64) et profite de fichiers registres deux fois plus importants (128 Ko au lieu de 64 Ko par partition). La mémoire partagée des SM du GP100 passe de 96 à 64 Ko mais elle n'est associée qu'à deux partitions au lieu de 4 ce qui indique en réalité une augmentation relative de 33%.
Ces représentations des architectures sont avant tout des vues d'esprit conçues par le département de marketing technique. Ainsi il est probablement correct de voir les choses sous un angle plus simple et d'imaginer un SM doté de 4 partitions pour Pascal T mais avec une mémoire partagée étendue à 128 Ko et une bande passante doublée. Il devait cependant être tentant de privilégier une communication technique sur 60 (petits) SM plutôt que sur 30 (gros) SM pour mettre en avant le GP100 dans le monde du GPU computing.
Quoi qu'il en soit, Pascal T et Pascal G diffèrent sur plusieurs points. Tout d'abord, la puissance de calcul en double précision correspond à la moitié de la simple précision sur la première alors qu'elle chute à un débit de 1/32ème sur la seconde. Ensuite la quantité de mémoire disponible par partition est doublée sur Pascal T, ce qui permet de maintenir une bonne occupation des unités de calcul lorsque des programmes complexes sont exécutés (et qui ont par exemple besoin de beaucoup de registres). Deux points peu importants dans le cadre du jeu vidéo et qui justifient donc cette différence au niveau des architectures du GP100 et du GP104.
Enfin, il y a au niveau des SM une troisième différenciation importante que nous n'avons pas encore abordée : le calcul en demi-précision ou FP16. Les unités de calcul 32-bit de Pascal T supportent un ensemble d'instructions supplémentaires qui au lieu d'une opération 32-bit regroupent 2 opérations de type FP16. De quoi potentiellement doubler la puissance de calcul pour les algorithmes qui peuvent se contenter d'une précision limitée (c'est le cas du deep learning) et quand le compilateur parvient à profiter pleinement de ce type d'instructions.
Certains ont pu penser que cela implique un support généralisé de la demi-précision pour les GPU Pascal, pour booster les performances et/ou réduire l'empreinte énergétique. C'est un compromis que font certains GPU mobiles, y compris les Tegra de Nvidia, mais il n'en est rien ici. Le support du FP16 pour Pascal T est spécifique au GPU computing et par conséquent n'est pas présent sur Pascal G.
GP104 : quelques unités de plus et un bond en fréquence
Après avoir passé en revue le coeur de l'architecture Pascal G, il est temps de se pencher sur le GP104 dans son ensemble. Voici le traditionnel schéma communiqué par Nvidia :
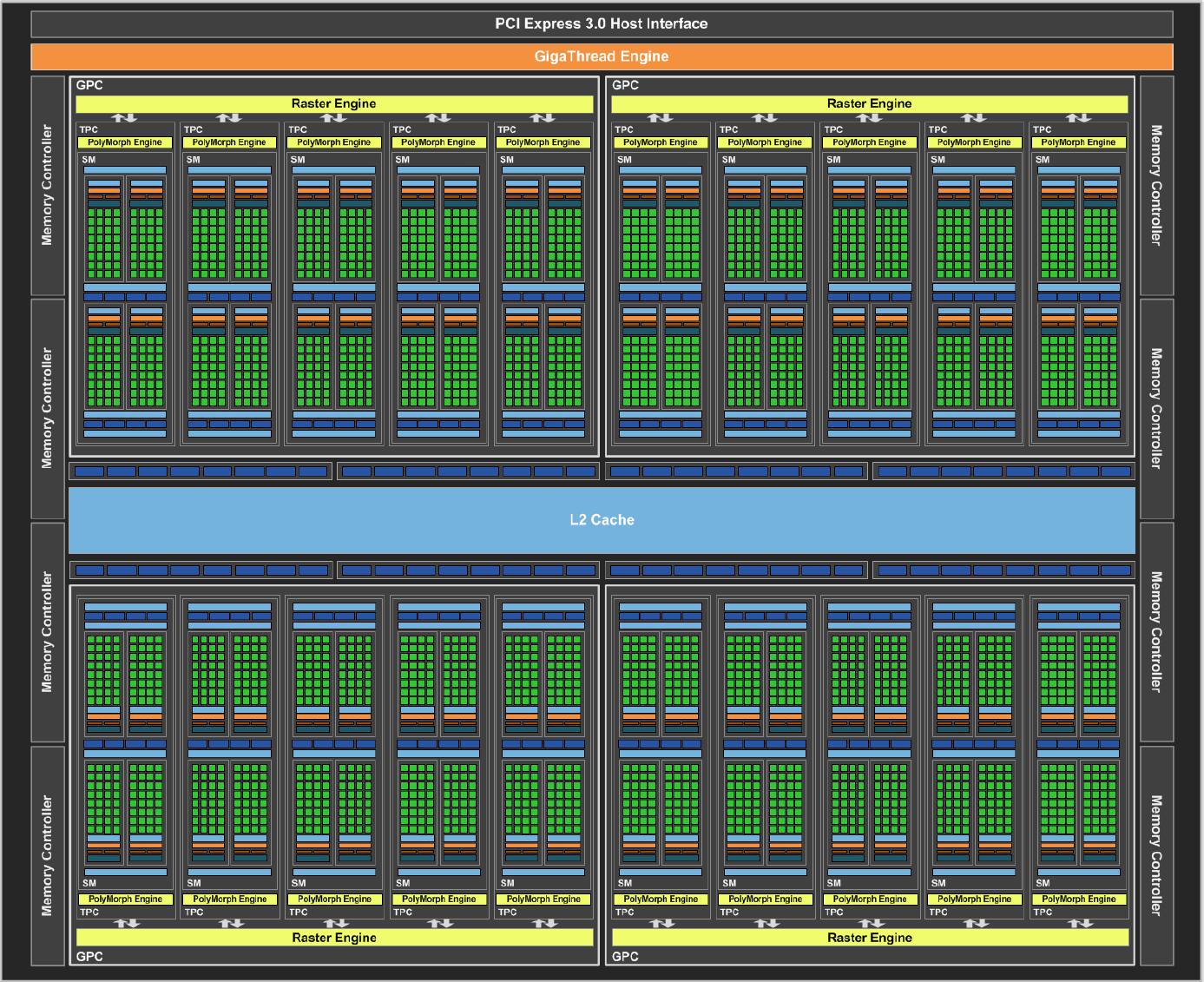
Nous pouvons y observer 4 GPC contenant chacun 5 SM. Une organisation interne proche de celle du GM204, lui aussi équipé de 4 GPC mais qui se contentent de 4 SM. Chaque SM de ces GPU intègre 128 unités de calcul 32-bit (les "cores"), ce qui nous en donne un total de 2560 pour le GP104 contre 2048 pour le GM204, une progression de 25%. Les unités de texturing, 8 par SM, progressent dans la même proportion. Pour le reste nous retrouvons un même cache L2 de 2 Mo ainsi qu'un même ensemble de 64 ROP associés à un bus mémoire de 256-bit réparti sur 8 contrôleurs 32-bit.
Voici pour comparaisons les spécificités de quelques GPU :
- GP100 : 6 GPC, 60 SM, 3840 FP32, 128 ROP ?, bus 4096-bit, 4096 Ko de L2
- GM200 : 6 GPC, 24 SM, 3072 FP32, 96 ROP, bus 384-bit, 3072 Ko de L2
- GK110 : 5 GPC, 15 SM, 2880 FP32, 48 ROP, bus 384-bit, 1536 Ko de L2
- GP104 : 4 GPC, 20 SM, 2560 FP32, 64 ROP, bus 256-bit, 2048 Ko de L2
- GM204 : 4 GPC, 16 SM, 2048 FP32, 64 ROP, bus 256-bit, 2048 Ko de L2
- GK104 : 4 GPC, 8 SM, 1536 FP32, 32 ROP, bus 256-bit, 512 Ko de L2
25% d'unités de calcul et de texturing en plus, aucune augmentation du nombre de ROP ou de la largeur de l'interface mémoire Vu comme ça le GP104 et cette première exploitation du 16 nm n'impressionne pas réellement. C'est cependant sans compter sur un point crucial : les fréquences !
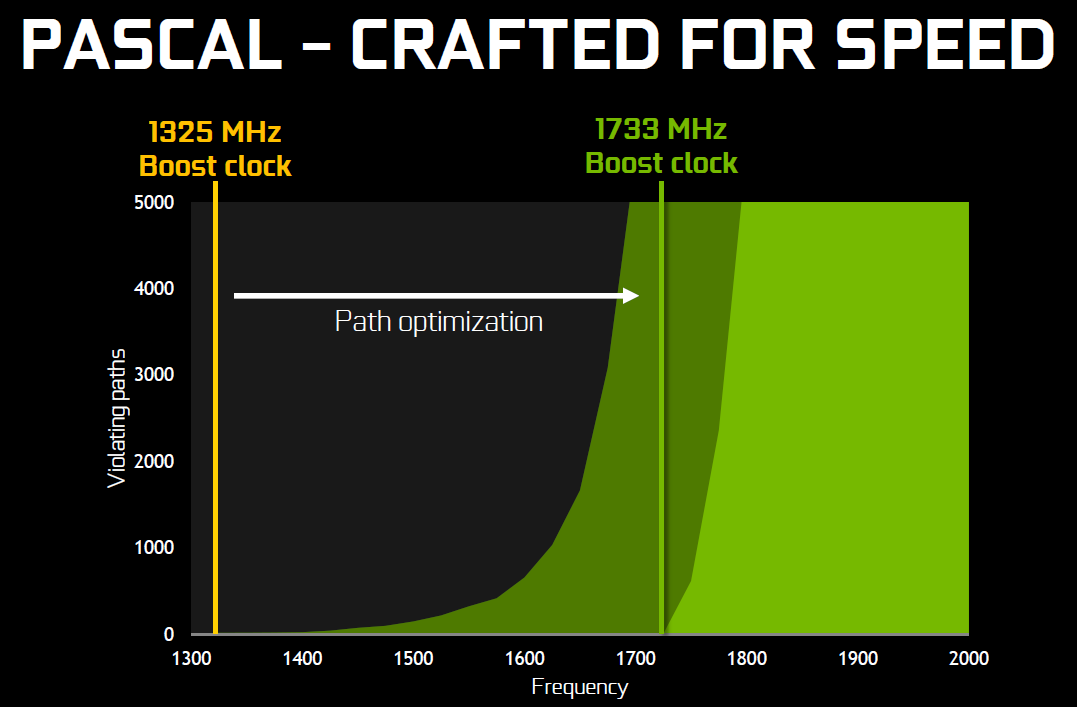
Nvidia nous avait indiqué ne pas avoir travaillé particulièrement les fréquences du GP100, qui profite simplement des gains automatiques liés au 16 nm, mais il en va tout autrement pour le GP104. Nvidia explique avoir passé en revue le moindre circuit du GPU pour retravailler tout point faible qui entravait la montée en fréquence. De quoi pouvoir proposer une fréquence turbo de référence de 1733 MHz sur la GTX 1080 soit un bond énorme de 40% par rapport aux 1216 MHz du GM204 qui équipe la GTX 980. Et cela tout en laissant une marge d'overclocking similaire puisqu'il est aisé d'atteindre plus de 2 GHz avec le GP104 !
Si nous combinons les +25% d'unités de calcul et les +40% en fréquence, cela nous donne cette fois une progression bien plus intéressante de la puissance brute par rapport au GM204 : +75%. Reste un bus mémoire limité à 256-bit, mais là aussi Nvidia pousse la fréquence en retravaillant les circuits de ses interfaces et en ayant recours à un nouveau type de mémoire : la GDDR5X.

Alors que la GDDR5 plafonne à 8 Gbps, la GDDR5X est prévue pour évoluer progressivement de 10 à 16 Gbps. Pour atteindre un tel débit la GDDR5X supporte un nouveau mode de transfert des données de type QDR permettant de doubler à fréquence égale le débit avec en contrepartie un prefetch et des accès qui sont également doublés à 16n et 512 bits. Deux points qui ne sont pas de réels problèmes pour les GPU alors qu'ils peuvent profiter d'un bus plus rapide avec une fréquence réduite pour les cellules mémoires, ce qui est bénéfique sur le plan de la consommation.
Sur la GTX 980, le GM204 est associé à de la GDDR5 7 Gbps, mais sur la GTX 1080, le GP104 profite des premiers modules GDDR5X 10 Gbps, un gain de 42%. Et ce n'est pas tout, le passage au 16 nm permet à Nvidia de complexifier son système de compression sans perte du framebuffer. Plus spécifiquement, c'est le codage différentiel pour les couleurs, également appelé compression delta, qui progresse à nouveau.
Pour rappel, son principe de base consiste à ne pas enregistrer directement la couleur mais sa différence par rapport à une autre qui fait office de repère. Ce n'est bien entendu utile que quand l'écart entre deux couleurs est suffisamment faible, de manière à ce que cette information représente moins de bits que la couleur en elle-même.

Pascal améliore tout d'abord la compression 2:1, dans le sens où elle s'enclenche dans plus de cas. Ensuite, un nouveau mode de compression 4:1 fait son apparition et est exploité quand le différentiel de couleur est très faible. Enfin, un mode 8:1 permet de combiner la compression classique des blocs de 2x2 pixels de couleur identique avec la compression delta 2:1.
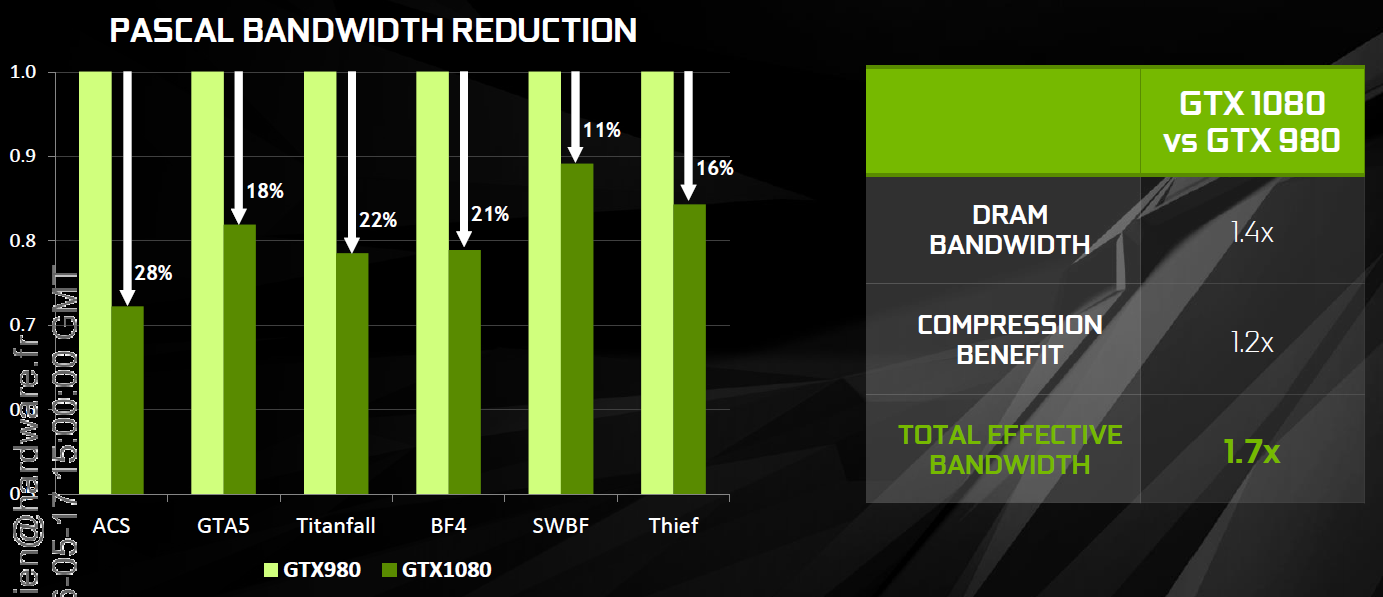
Les outils de Nvidia mettent en avant une réduction significative de la bande passante mémoire nécessaire par image par rapport aux GPU Maxwell, ce qui transformerait ces optimisations en augmentation de 20% de la bande passante effective. Couplée à la GDDR5X 10 Gbps, le GP104 de la GTX 1080 profiterait ainsi d'une progression totale de sa bande passante effective de 70%, ce qui permet de maintenir l'équilibre par rapport à sa puissance de calcul.
Pour démontrer que sa technologie a réellement un impact en jeu, Nvidia fourni des screenshots de Project Cars sur lesquels les zones compressées sont représentées en fushia :

[ Sans compression ] [ Sur GPU Maxwell ] [ Sur GPU Pascal ]
A noter que cette amélioration de la compression sans perte permet également de retenir plus de données dans le cache L2 et de réduire la taille de certains transferts entre ce dernier et les SM, ce qui peut profiter aux performances.
2 - GP104 : 7.2 milliards de transistors en 16 nm
3 - Pascal et Async Compute : du mieux ?
4 - Pascal et le SMPE pour la VR et le surround
5 - SLI amélioré, Fast Sync, Moteur vidéo HDR
6 - Spécifications et Direct3D 12
7 - La GeForce GTX 1080 Founders Edition
8 - Protocole de test
9 - Performances théoriques : pixels
10 - Performances théoriques : géométrie
11 - Fermi vs Kepler vs Maxwell vs Pascal
12 - Consommation, efficacité énergétique
13 - Nuisances sonores, températures, photos IR
14 - Benchmark : 3DMark Fire Strike
15 - Benchmark : Anno 2205
16 - Benchmark : Ashes of the Singularity
17 - Benchmark : Battlefield 4
18 - Benchmark : Crysis 3
20 - Benchmark : DOOM
21 - Benchmark : Dying Light
22 - Benchmark : Evolve
23 - Benchmark : Fallout 4
24 - Benchmark : Far Cry Primal
25 - Benchmark : Grand Theft Auto V
26 - Benchmark : Hitman
27 - Benchmark : Project Cars
28 - Benchmark : Rise of the Tomb Raider
29 - Benchmark : Star Wars Battlefront
30 - Benchmark : The Division
31 - Benchmark : The Witcher 3 Wild Hunt
32 - Récapitulatif des performances
33 - GPU Boost : pourquoi ? comment ?
34 - Overclocking : 2 GHz à portée de click
35 - Conclusion
Contenus relatifs
- [+] 26/10: Nvidia pré-annonce les GeForce GTX ...
- [+] 17/10: Destiny 2 de retour chez Nvidia
- [+] 27/09: Nvidia offre Middle Earth: Shadow o...
- [+] 22/08: Destiny 2 de nouveau offert chez Nv...
- [+] 14/06: Destiny 2 pour les GTX 1080 et 1080...
- [+] 31/05: Computex: Nvidia annonce les GTX 10...
- [+] 29/05: Desktop, mobile et en box : la GTX ...
- [+] 25/04: Les GTX 1080 et 1060 ''OC'' disponi...
- [+] 28/03: For Honor ou Ghost Recon en bundle ...
- [+] 01/03: GDC: Nvidia va proposer des GTX 108...