
Architecture Vega 10 : AMD lève le voile



A l'occasion du CES, AMD nous en dit un petit peu plus sur le futur GPU Vega 10 et dévoile quelques points techniques de son architecture qui vont permettre d'améliorer le rendement en jeu et de monter en puissance dans le monde de l'intelligence artificielle.

Suivant la même formule que l'an passé avec Polaris, AMD a décidé de nous aider à patienter en dévoilant quelques éléments de sa nouvelle architecture GPU, dont le premier exemplaire, Vega 10, vise le haut de gamme et est annoncé pour le premier semestre 2017.
Au menu : une refonte du sous-système mémoire pour pouvoir prendre en charge une masse de données toujours plus imposantes, de nouveaux moteurs géométriques pour mieux traiter des décors plus riches, de nouveaux moteurs de rastérisation pour calculer moins de pixels inutiles et des unités de calcul plus efficaces pour donner un coup de boost à leurs performances.
A travers cette annonce, AMD explique avec quelques détails techniques comment ces évolutions ont été mises en place.

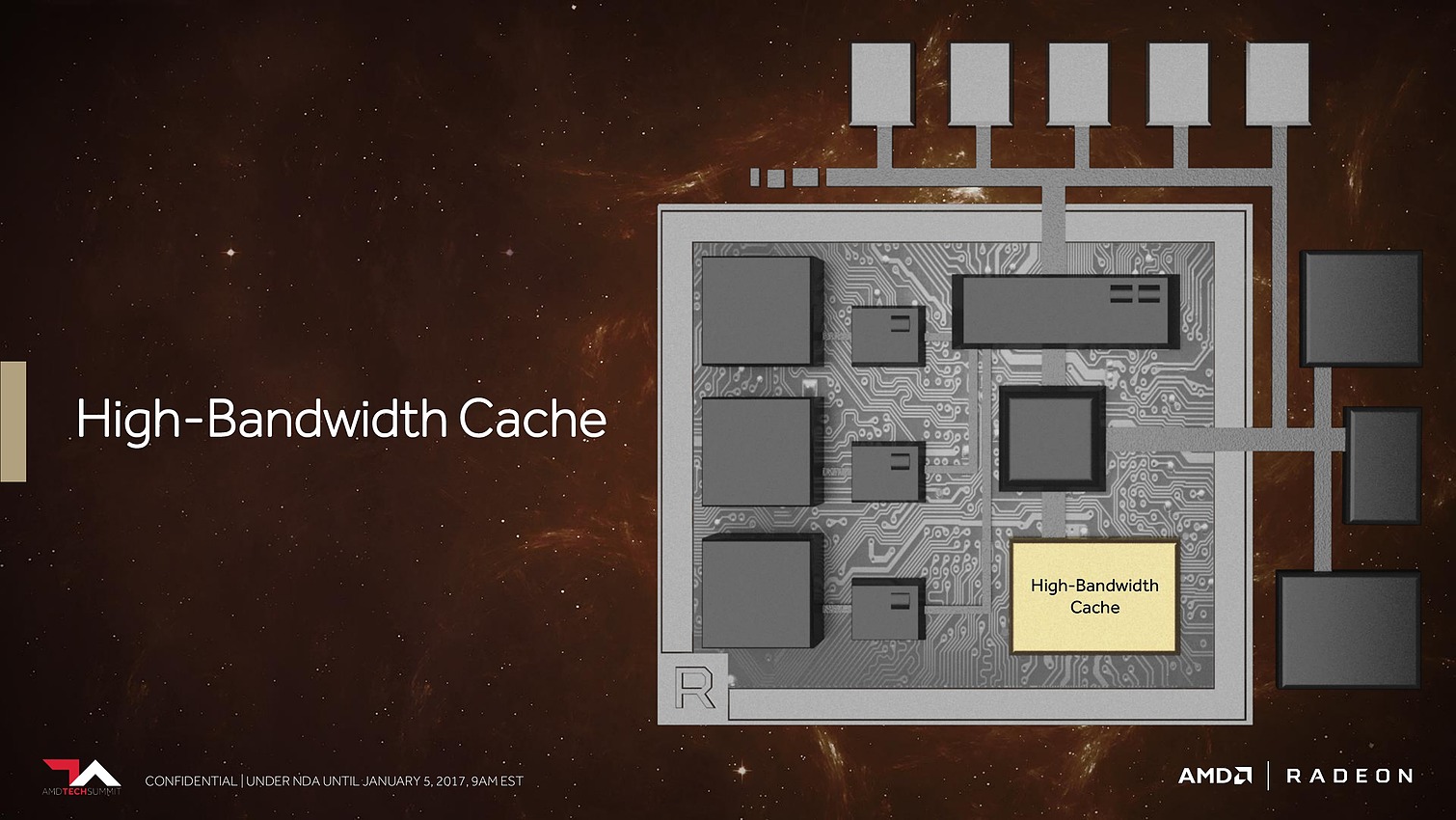




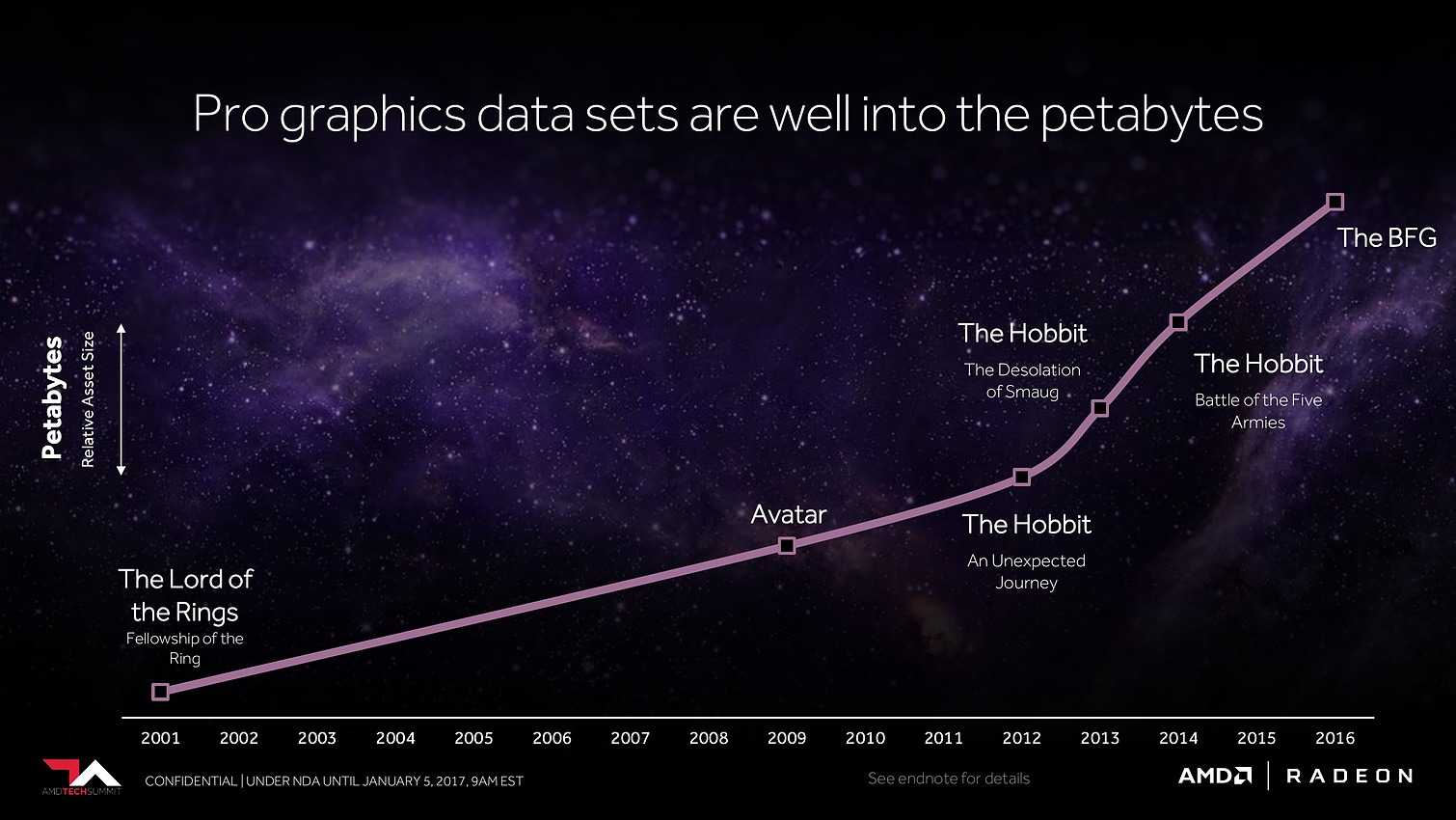
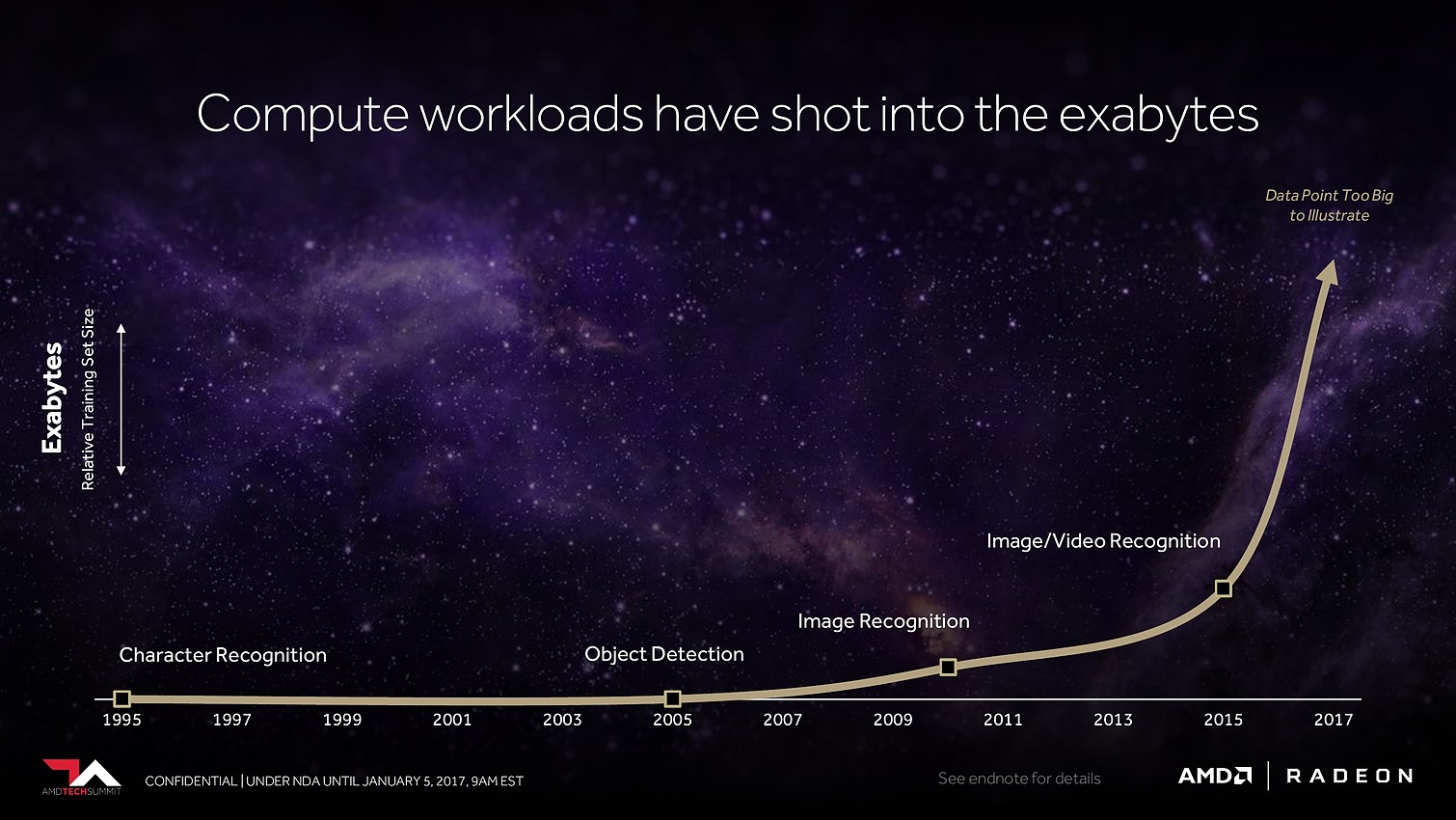
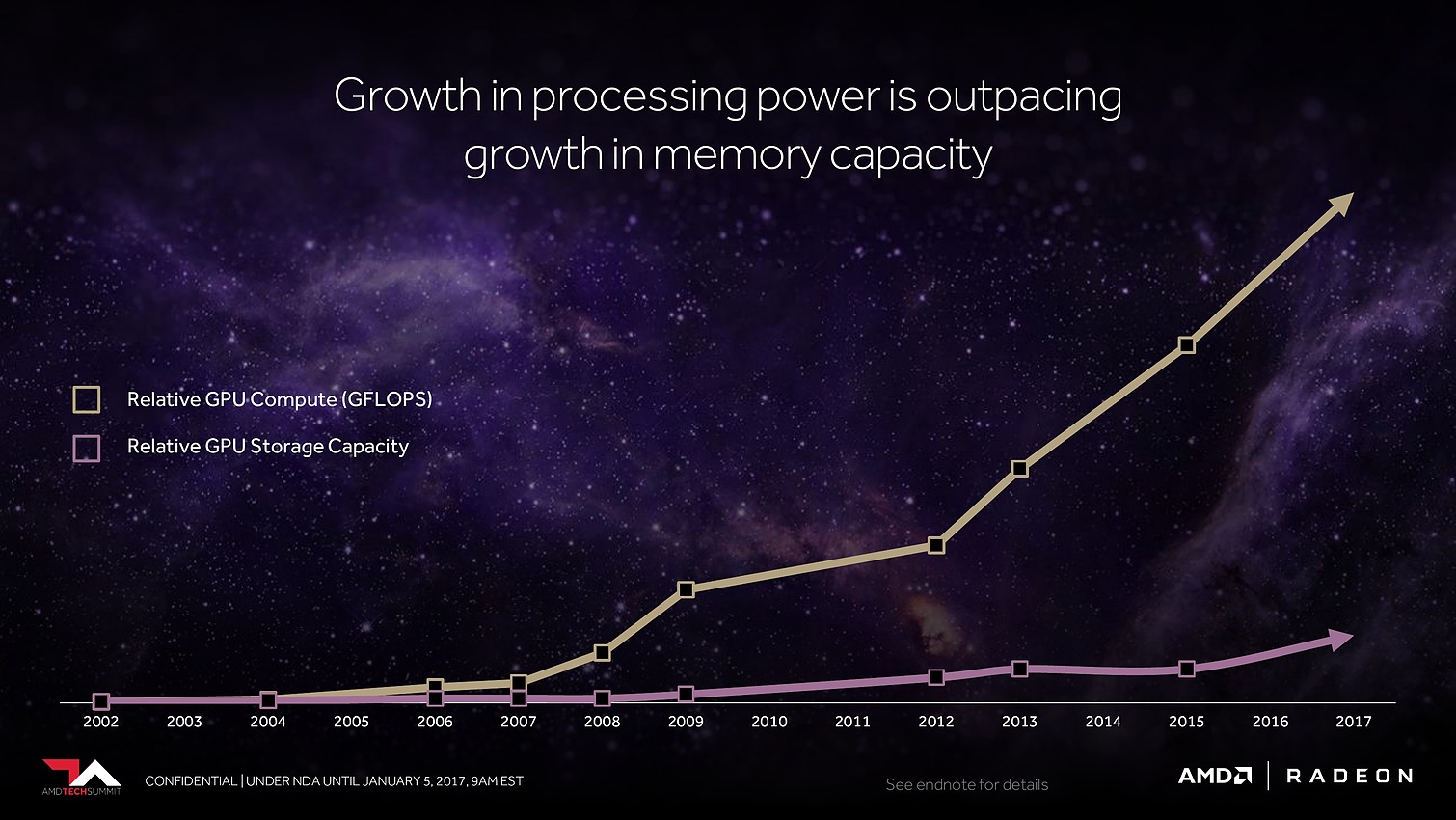
Avec Vega, AMD annonce avoir mis en place l'architecture mémoire pour GPU la plus avancée du marché, pour pouvoir répondre aux besoins actuels et futurs dans les domaines où la taille des data sets est en train d'exploser. Il serait déjà question de pétaoctets dans l'animation 3D voire même d'exaoctets dans le GPU computing et l'intelligence artificielle. Pour s'y attaquer, Vega est capable d'adresser jusqu'à 512 To grâce à un espace de mémoire virtuelle étendu (49-bit) qui va au-delà des 256 To du x64 (48-bit).
Bien entendu, le GPU Vega 10 ne recevra pas autant de mémoire dédiée. Il sera associé à 2 modules de mémoire HBM2 pour un bus combiné de 2048-bit. Sur base des premiers modules disponibles qui sont de type 4 Go (4-Hi), Vega 10 sera ainsi associé à 8 Go de HBM2, mais pourra passer à 16 Go quand les modules 8-Hi seront disponibles.
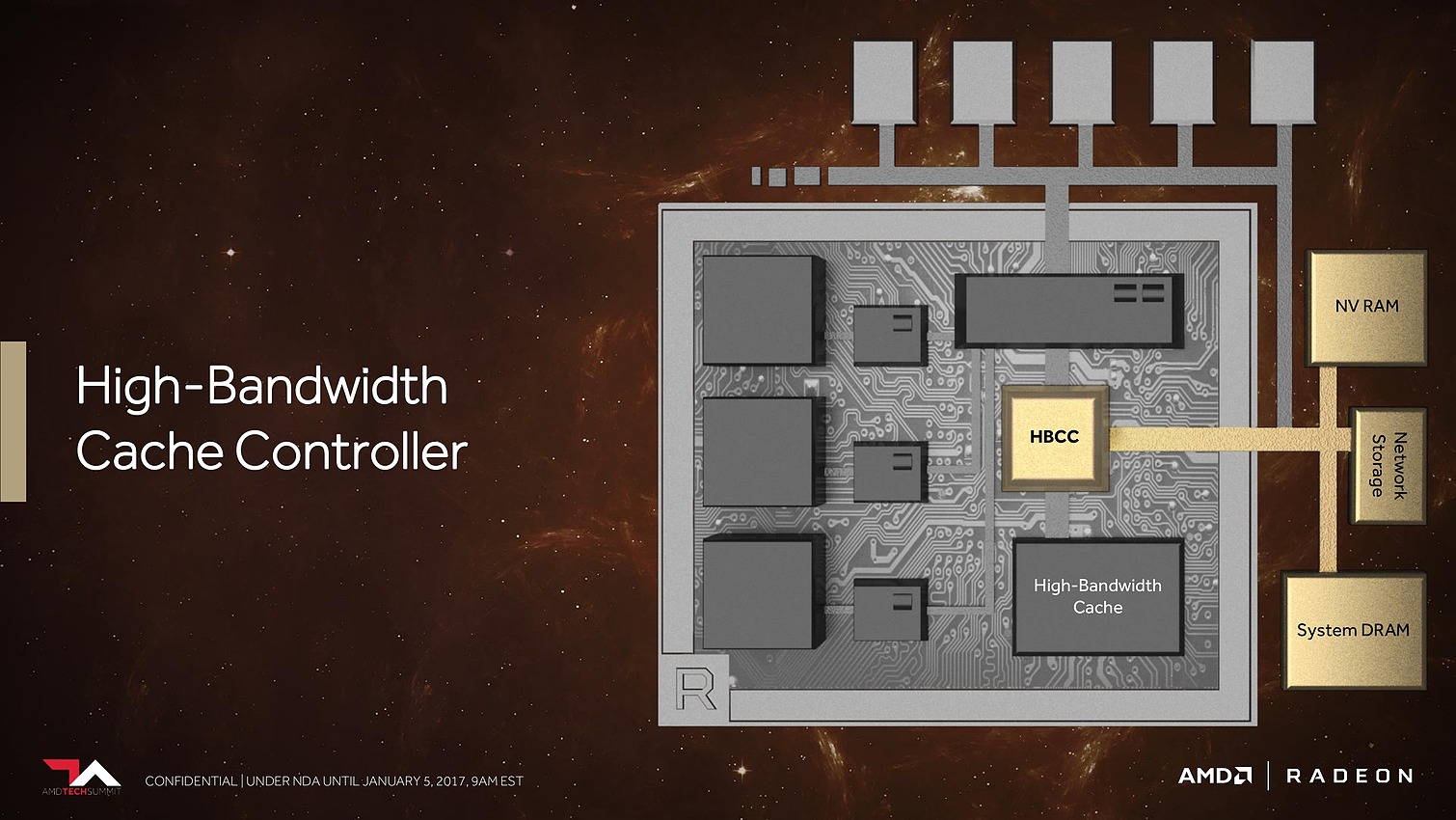
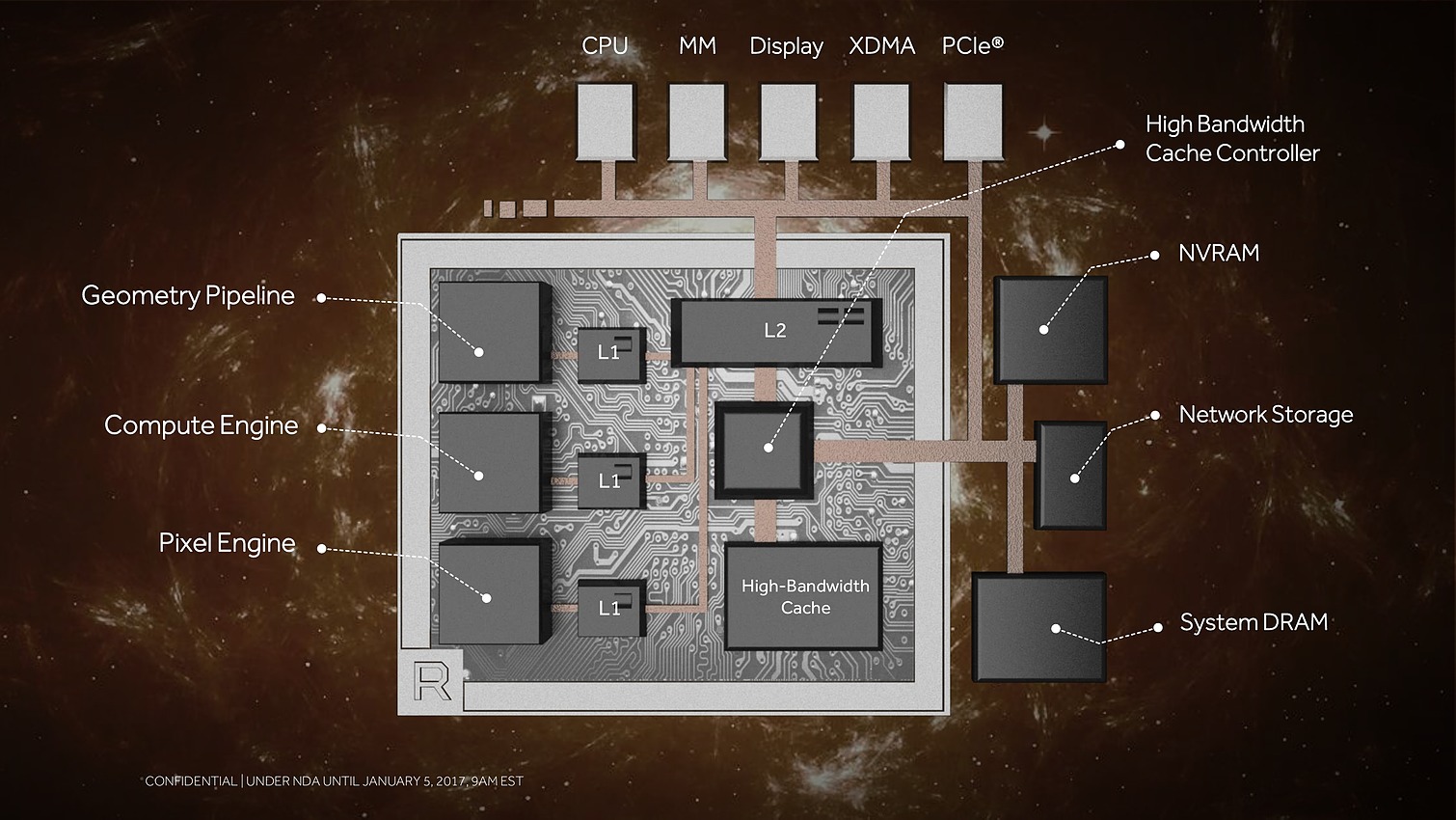
8 Go, voire 16 Go, c'est bien peu par rapport aux data sets auxquels AMD compte s'attaquer. Pour pouvoir s'y attaquer plus efficacement, AMD a revu le contrôleur mémoire qui s'appelle dorénavant High Bandwidth Cache Controller alors que la mémoire HBM2 est présentée comme un cache local (High Bandwidth Cache). Le HBCC a été conçu et optimisé pour piloter les mouvements de données à partir de l'énorme espace adressable. Qu'elles se situent dans la mémoire système, dans de la flash rattachée au GPU ou ailleurs sur le réseau, le but est faire en sorte qu'à chaque instant un maximum de données utiles se retrouvent dans la HBM2.
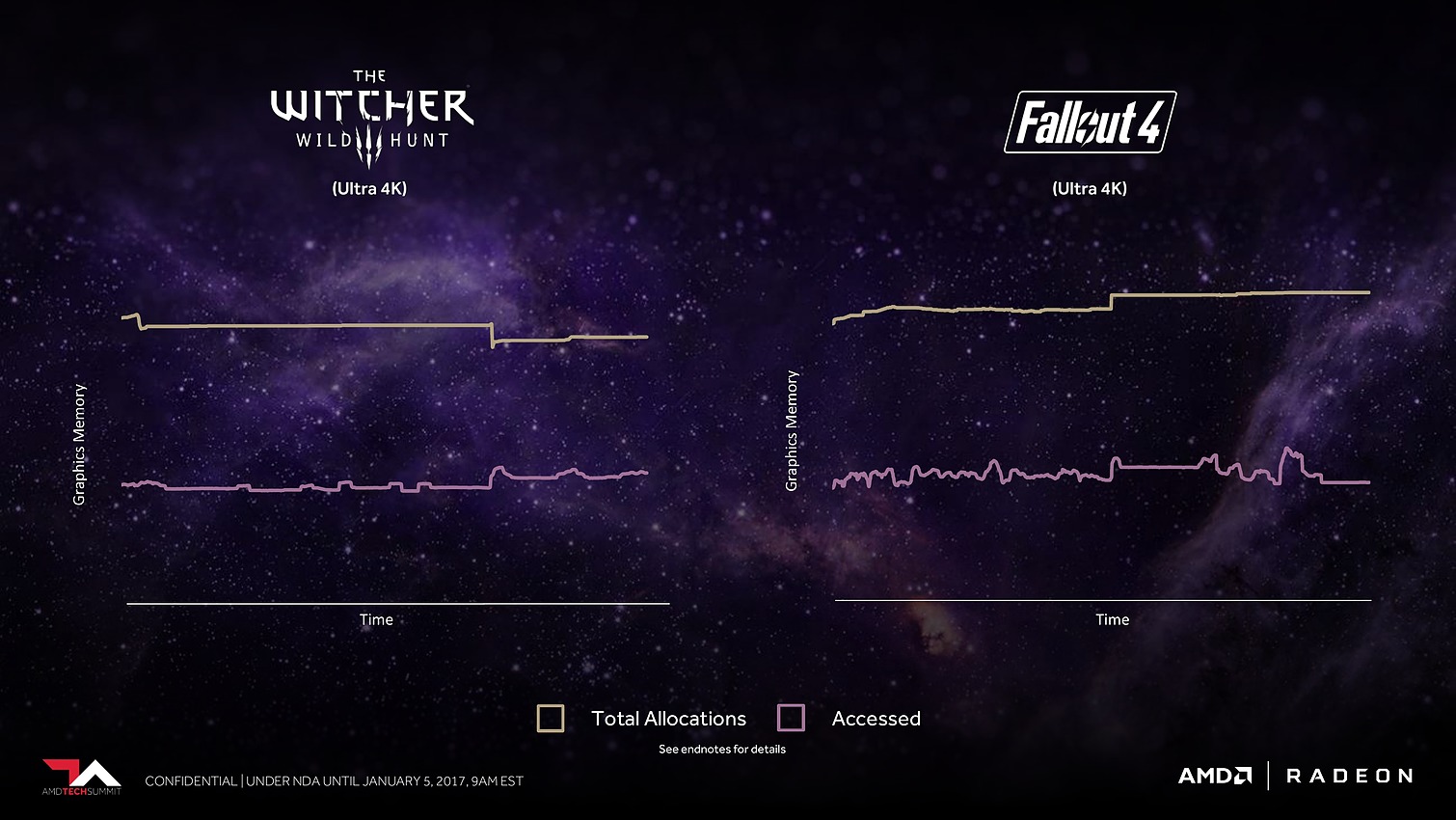
C'est évidemment principalement important dans le monde professionnel, mais AMD en parle également au niveau des jeux vidéo, probablement pour anticiper les critiques par rapport à une mémoire de "seulement" 8 Go contre 12 Go sur une Titan X de Nvidia. A ce sujet, AMD explique que pour chaque image générée moins de la moitié de la mémoire utilisée est réellement exploitée. Il y a donc des opportunités d'optimisation et le HBCC est annoncé comme capable de faire mieux que les contrôleurs et pilotes classiques.
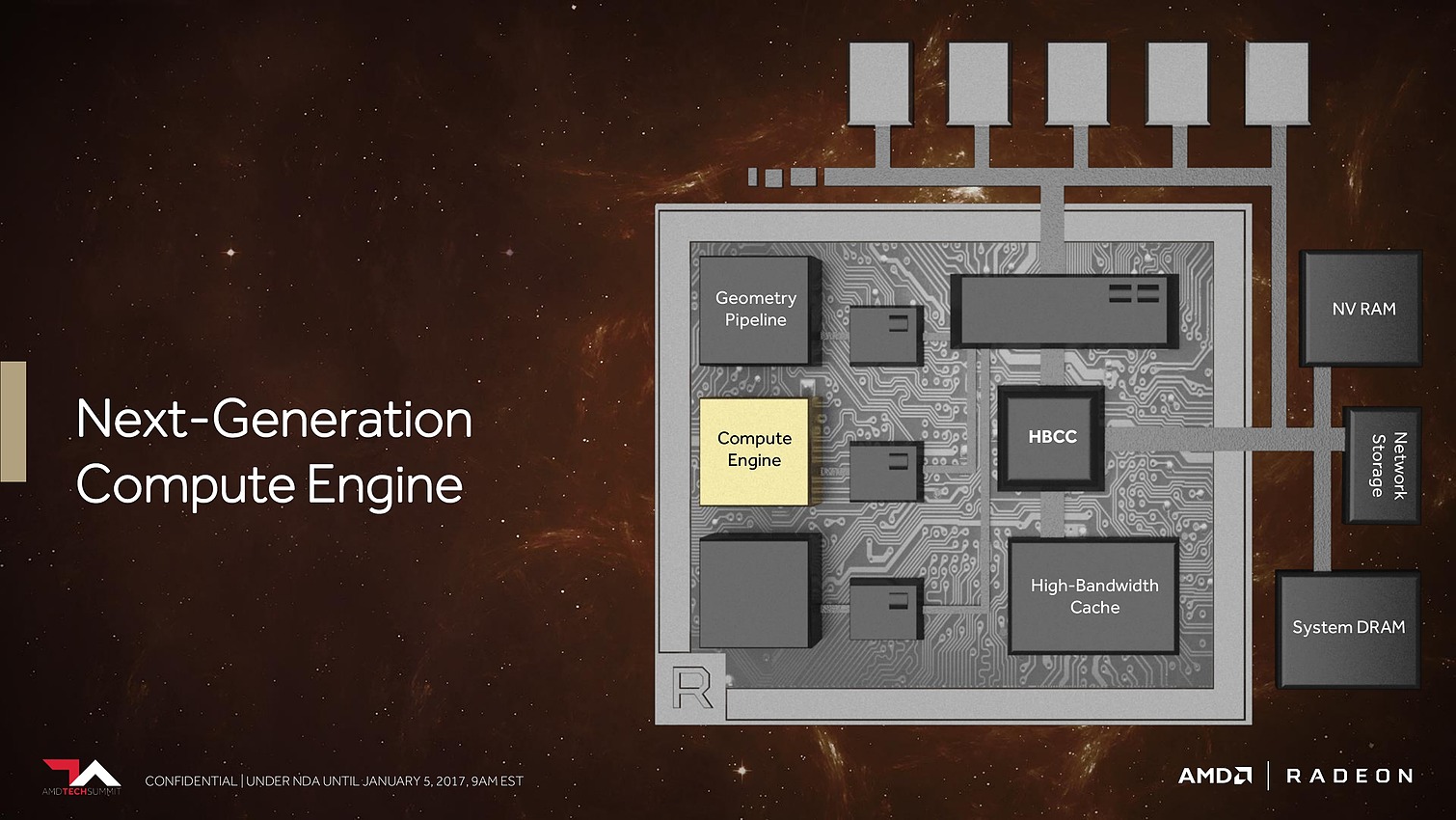



Ensuite, ce sont évidemment les unités de calcul qui vont recevoir quelques améliorations. AMD explique tout d'abord les avoir retravaillées pour autoriser une montée en fréquence significative, et réduire l'écart avec Nvidia sur ce point. Mais ce n'est pas tout et le taux d'IPC devrait également progresser. AMD en dit peu à ce niveau et s'est contenté de nous indiquer avoir élargi le cache d'instructions, ce qui boosterait notamment le débit d'opérations sur 3 opérandes. Reste évidemment à voir à quel niveau se situeront les gains en pratique pour ces Next-Gen Compute Units (NCU).
L'autre grosse nouveauté concernant les unités de calcul est le packed math qui représente le support natif de la démi précision ou FP16. Pour rappel, les GPU GCN 3 (Tonga/Fiji) et GCN4 (Polaris), supportent déjà le FP16 mais uniquement pour gagner de la place au niveau des registres, les opérations étant traitées par les unités de calcul FP32 à débit identique.
Avec Vega, chaque SIMD d'unité de calcul FP32 pourra travailler sur des vecteurs 2-way en FP16. C'est identique à ce que fait Nvidia sur le GP100 ou sur Tegra et cela permet de doubler la puissance de calcul en demi précision si le compilateur arrive à extraire des paires d'opérations à traiter en parallèle. AMD précise que si ce n'est pas le cas, des gains pourront malgré tout ressortir au niveau de la consommation énergétique, et que son approche permet de gérer indépendamment les parties hautes et basses des registres pour plus d'efficacité.
Enfin, AMD a ajouté le support du calcul en 8-bit mais il est spécifique au deep learning, comme le fait Nvidia sur GP102/104/106/107). Contrairement au FP16 il ne s'agit donc pas d'un support généralisé mais d'une ou de quelques instructions spécifiques telles que DP4A (produit scalaire avec accumulation).
Au final, AMD parle donc par NCU de 128 ops 32-bit par cycle (= 64 FMA FP32 comme sur tous les GPU GCN), 256 ops 16-bit par cycle (= 128 FMA FP16) et de 512 ops 8-bit par cycle (= 64 DP4A). Aucune information concernant le débit en FP64 qui est juste annoncé comme configurable.
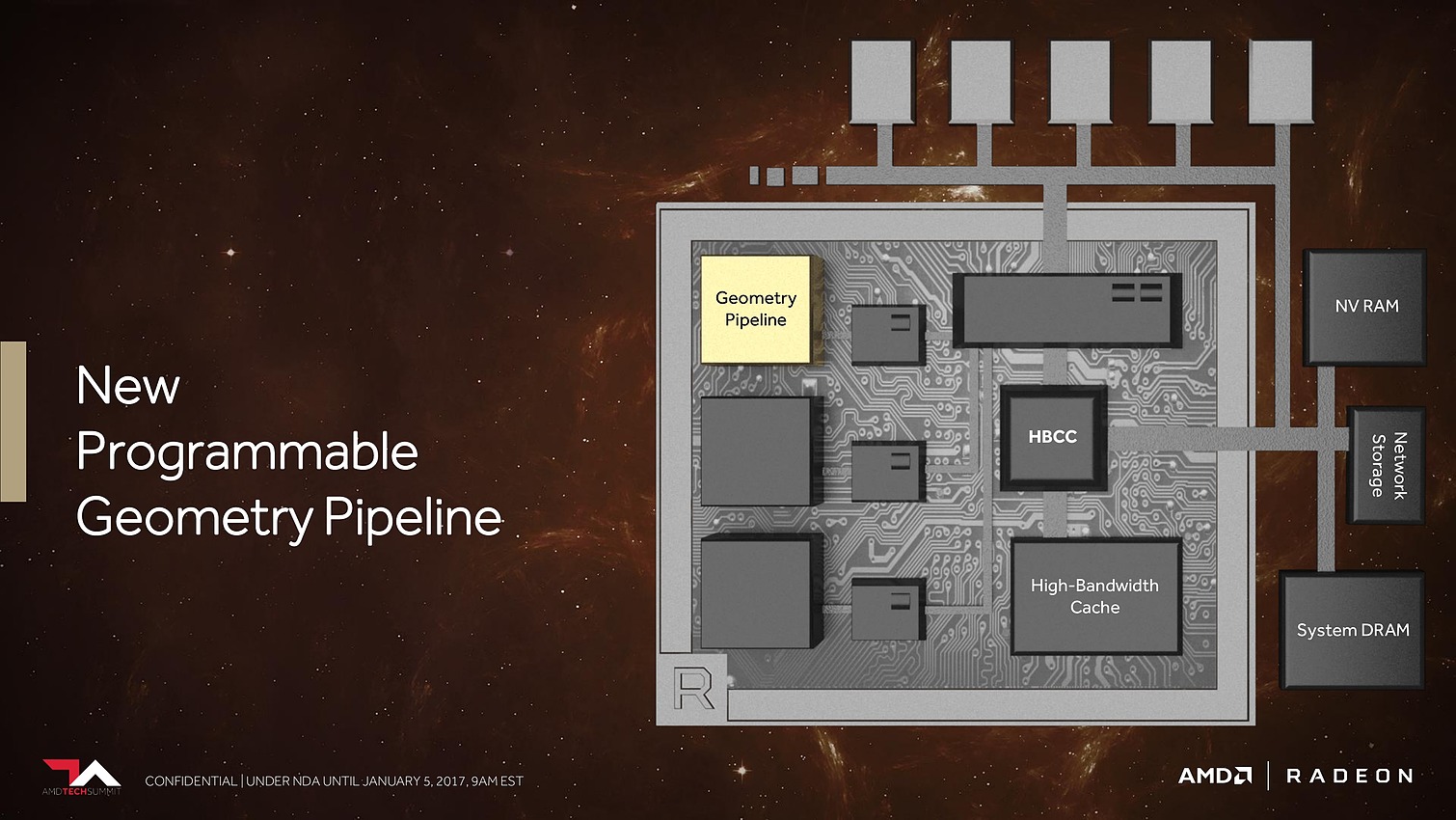

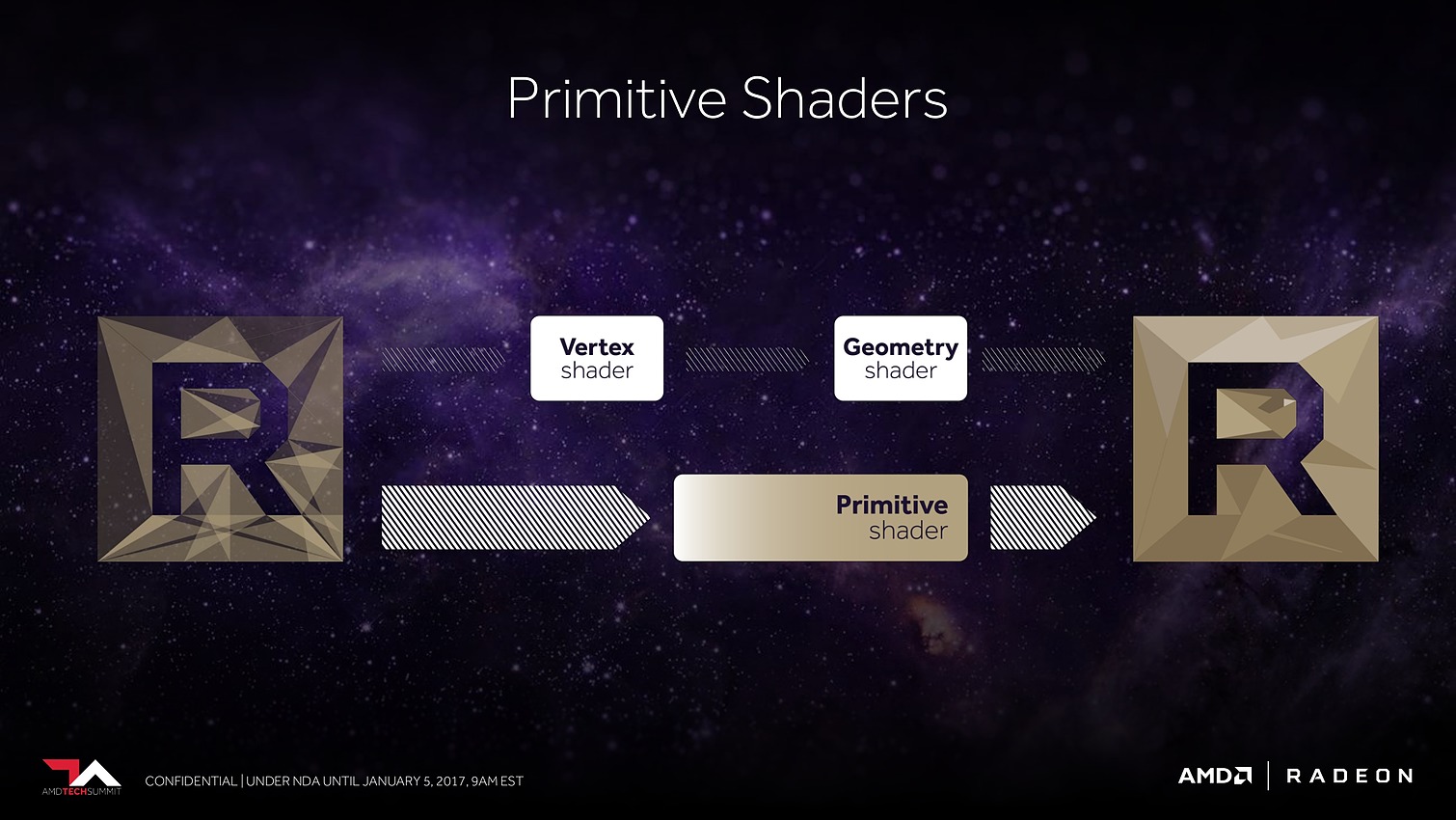
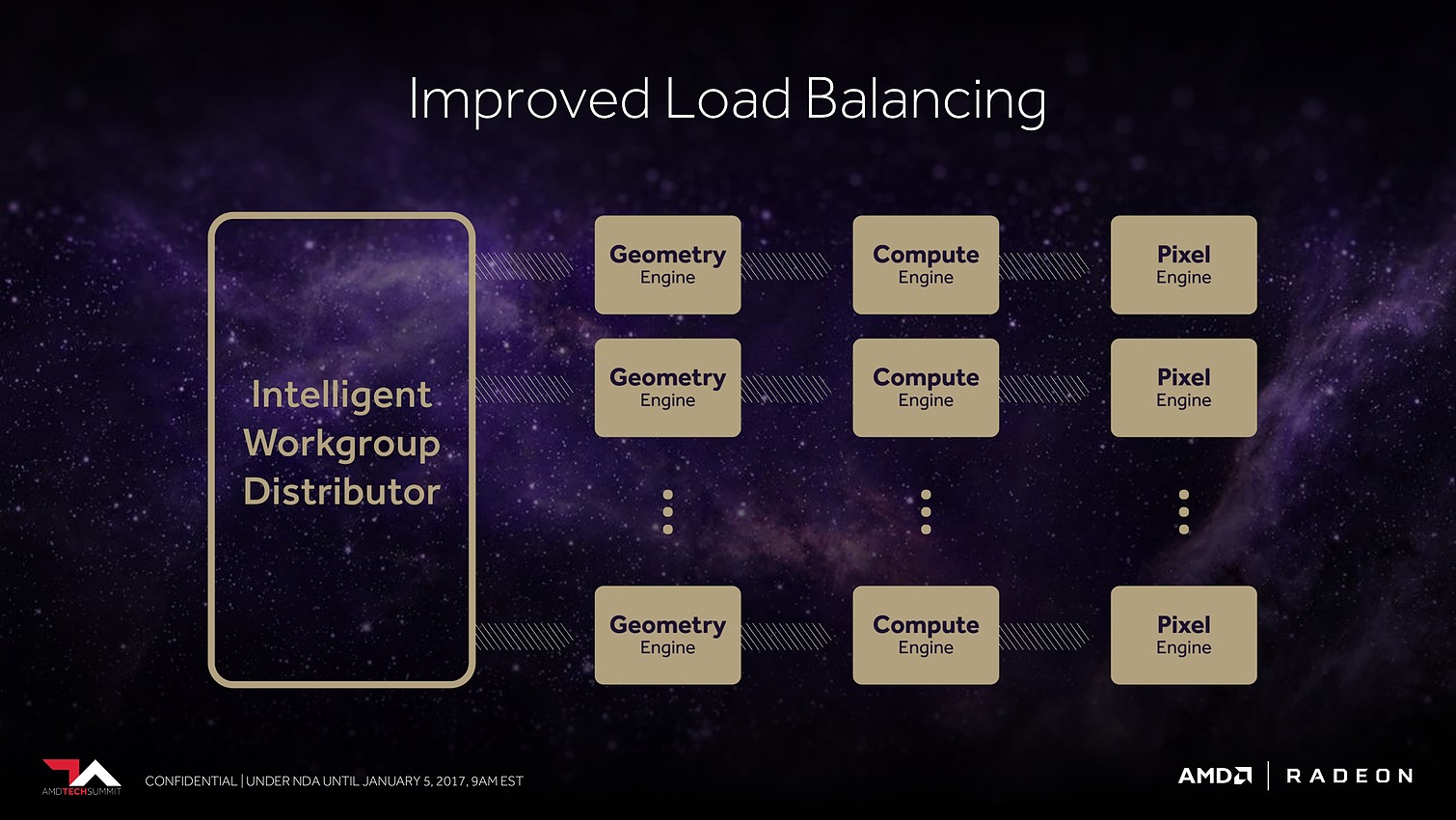
Plus spécifiquement pour le jeu vidéo cette fois, AMD a retravaillé ses moteurs géométriques sur 3 fronts. Tout d'abord leur débit va augmenter d'un facteur supérieur à 2x, AMD parle de 11 triangles par cycle avec 4 moteurs géométriques pour un GPU Vega, sans préciser s'il s'agit de Vega 10. Nous supposons qu'il s'agit ici du débit d'éjection des triangles qui tournent le dos à la caméra par exemple. Ce débit supérieur était jusqu'ici un des gros avantages des GPU Nvidia, qu'AMD devrait donc rattraper.
Ensuite, AMD proposera aux développeurs un nouveau type de shaders, les Primitive Shaders qui permettront de remplacer les Vertex Shaders et les Geometry Shaders. Nous ne savons pas exactement comment tout cela fonctionnera et sera exposé, mais cela devrait permettre de faciliter l'implémentation de pipelines de rendu personnalisés. AMD indique par ailleurs qu'ils permettront de booster le taux d'éjection des primitives mais nous ne savons pas si cela correspond au débit de 11 triangles par cycle noté ci-dessus ou si ce gain se fera en complément.
Enfin, suite à des retours constructifs de développeurs sur console, qui cherchaient à optimiser au maximum les performances, AMD s'est rendu compte que son algorithme de load balancing pouvait être amélioré pour mieux exploiter les ressources disponibles. Il a donc été revu.
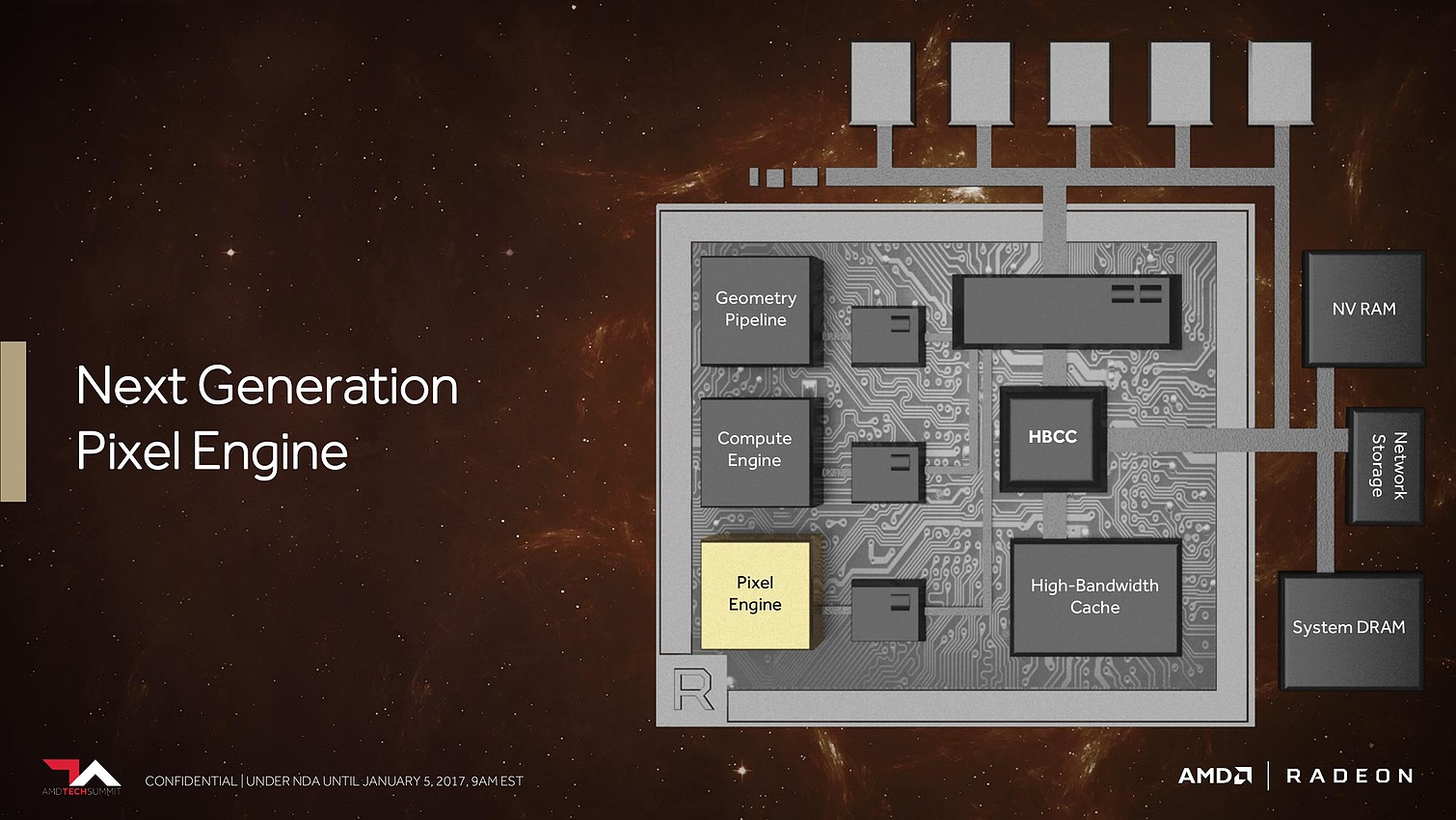

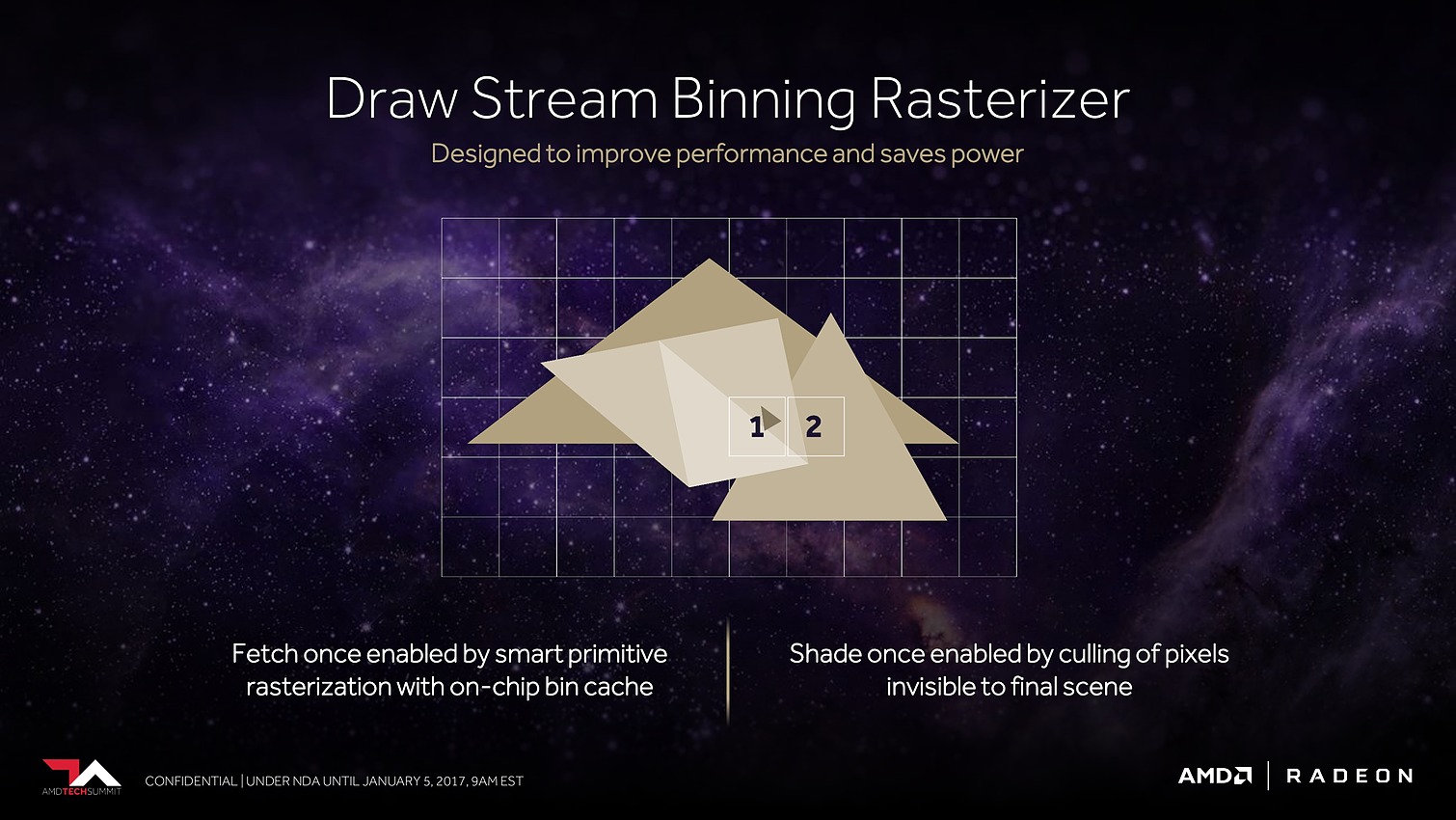

Le dernier point mis en avant par AMD concerne les pixels. Avec tout d'abord des moteurs de rastérisation revus. AMD parle de draw stream binning rasterizer. Derrière ce charabia technique se cache une approche similaire à celle exploitée par Nvidia sur les GPU Maxwell et Pascal. Elle consiste à faire une exploitation opportuniste du principe du tile renderingpour éviter de calculer trop de pixels masqués.
Il ne s'agit pas d'avoir recours à un rendu en 2 passes comme le font certains GPU mobiles pour appliquer fermement la technique, mais plutôt d'utiliser un petit buffer interne avant la rastérisation qui permet de traiter celle-ci quand l'information de couverture de plus de triangles est connue. Si ces informations permettent d'éviter de générer des pixels masqués, c'est tout bonus, si ce n'est pas le cas le traitement se fait de manière classique. D'où le côté opportuniste de la technique qui ne souffre pas des désavantages des approches des GPU mobiles.
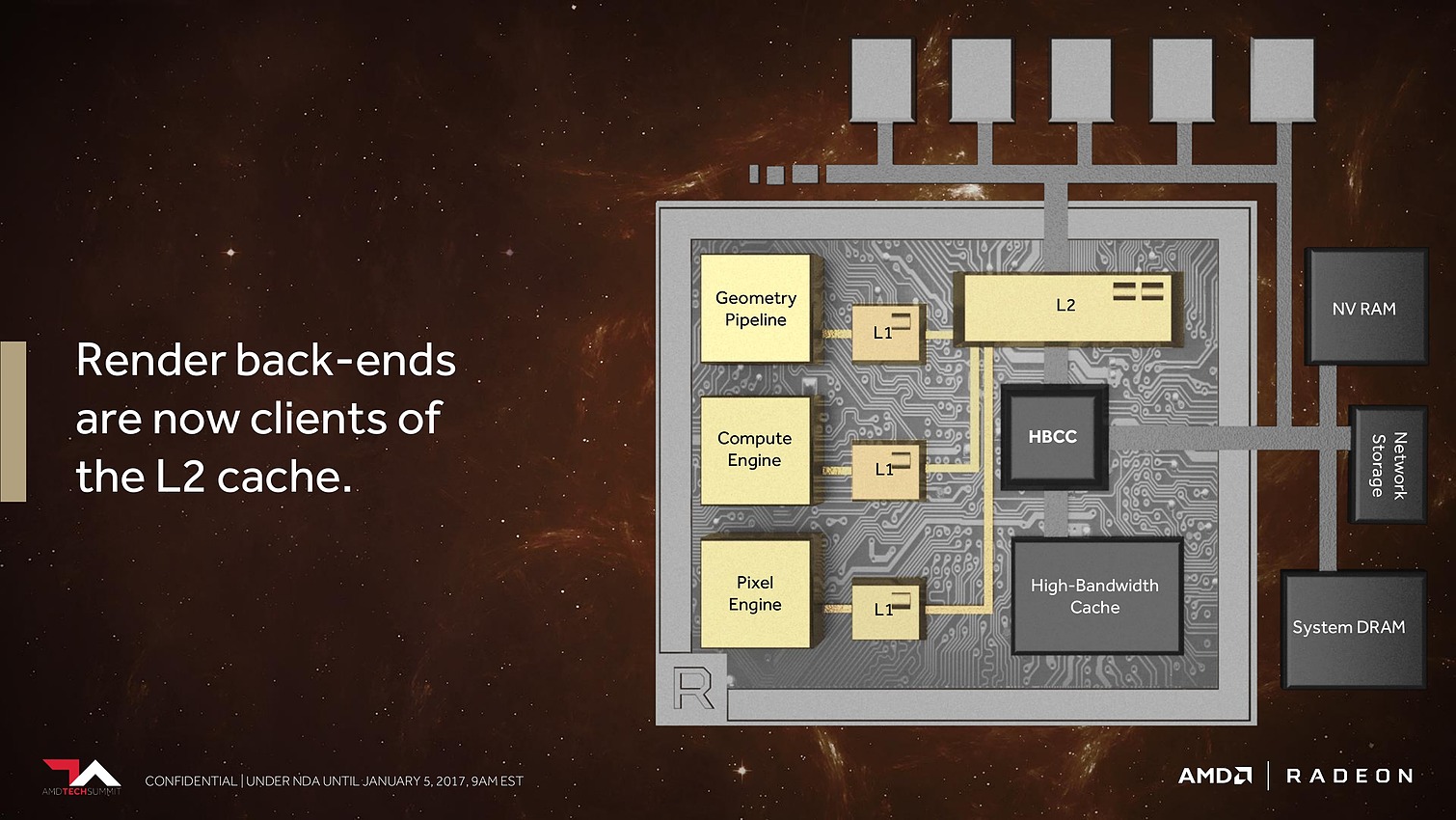
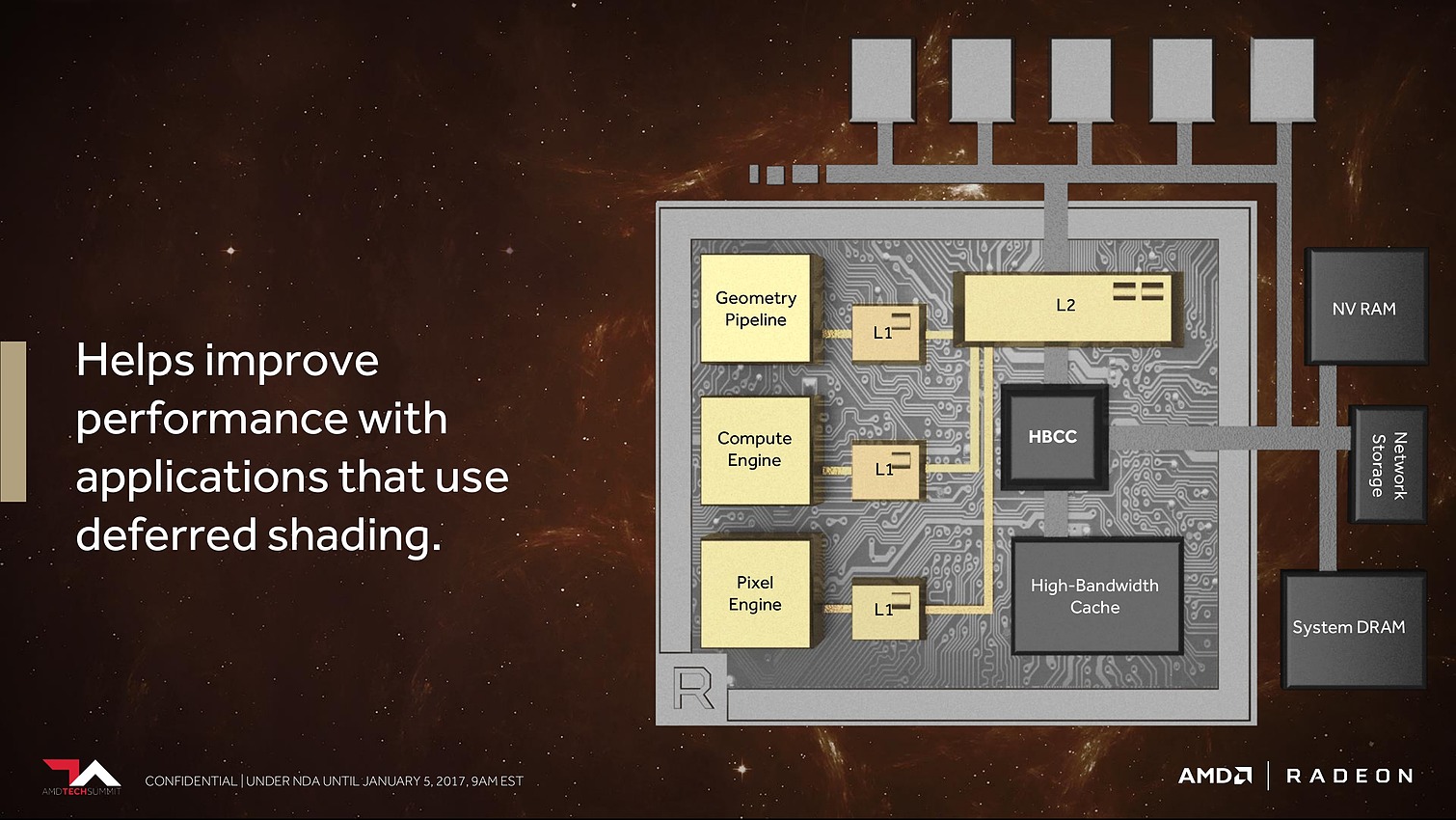
Les ROP ont eux aussi été revus. Leurs capacités exactes restent inconnues, mais au lieu d'exploiter de petits buffers spécifiques, ils deviennent des clients du gros cache L2. Selon AMD cela permet un gain appréciable dans les moteurs de type rendu différé qui sont devenus très courants dans les jeux vidéo.
Après ces quelques caractéristiques techniques de l'architecture Vega, intéressons-nous au GPU Vega 10 dans son ensemble. Physiquement tout d'abord puisque nous avons pu l'apercevoir brièvement dans les mains de Raja Koduri, responsable du groupe Radeon Technology (RTG) lors d'un évènement presse organisé par AMD le mois passé :

Nous pouvons apercevoir sur cette photo, prise rapidement au smartphone, un énorme die placé sur un interposer qui reçoit également 2 modules HBM2. Nous pouvons estimer la taille du die de Vega 10 entre 500 et 550 mm² (soit plus que les 471mm² du GP102, mais moins que les 610 mm² du GP100). C'est ce qui explique pourquoi AMD s'est contenté d'un bus 2048-bit, contrairement aux 4096-bit de Fiji dont les modules HBM1 prenaient beaucoup moins de place.
Pour pouvoir placer 4 modules HBM2 avec un gros die pour le GP100, Nvidia a de son côté recours à une double exposition très coûteuse, seule possibilité actuelle pour concevoir un interposer suffisamment grand pour recevoir l'ensemble. Avec Vega 10 AMD vise autant le marché professionnel que les joueurs et a donc opté pour une solution (un peu) plus raisonnable en termes de coûts de production.
Quelles pourraient être les spécifications complètes d'une Radeon basée sur le GPU Vega 10 ? Nous avons rassemblé dans le tableau qui suit nos suppositions actuelles basées sur les quelques éléments dévoilés par AMD, notamment lors de l'annonce de la Radeon Instinct MI25 :

Reste bien entendu que pour pouvoir réellement concurrencer le GP102 (Titan X), et pas seulement se contenter de battre le GP104 (GTX 1080), il faudra que les avancées dévoilées aujourd'hui par AMD portent réellement leurs fruits en pratique.
Est-ce que le HBCC sera efficace dans le cadre du jeu vidéo si 8 Go deviennent insuffisants ? Est-ce que le FP16 sera exploité par certains jeux ? Est-ce que les développeurs seront intéressés par les Primitive Shaders ? Est-ce que le boost au niveau du débit des moteurs géométrique se retrouvera en pratique ? Quel sera le gain réel en terme d'IPC ? La nouvelle approche pour la rastérisation permettra-t-elle de rattraper Nvidia en terme d'efficacité ?
A l'heure actuelle, AMD ne nous fournit aucune information ou donnée pour permettre de quantifier ou de se faire une idée de ce que tout cela va apporter. Nous ne pouvons pas oublier que les avancées dévoilées de la même manière pour Polaris ont au final produit des résultats mitigés par rapport aux espérances suscitées (nous avons noté 8% de mieux en jeu entre GCN3 et GCN4). Avec Vega, nous avons par contre l'impression qu'AMD a enfin pris le recul nécessaire pour observer ce que Nvidia a fait de bien pour rendre plus efficaces ses dernières générations de GPU. De quoi s'engager dans une voie similaire avec Vega, ce qui laisse augurer de bonnes choses. Nous sommes évidemment impatients d'en savoir plus !
Vous pourrez retrouver l'intégralité de la présentation d'AMD ci-dessous :











Contenus relatifs
- [+] 14/09: Pour quand les RX Vega Custom ? Oct...
- [+] 14/08: Preview : AMD RX Vega64 et RX Vega5...
- [+] 31/07: AMD lève le voile sur les RX Vega
- [+] 03/07: 1ers tests de la Radeon Vega Fronti...
- [+] 27/06: AMD lance la Radeon Vega Frontier E...
- [+] 17/05: Radeon Vega Frontier Edition 16 Go:...
- [+] 05/01: Architecture Vega 10 : AMD lève le ...
- [+] 12/12: Vega 10: 4096 unités, 1.5 GHz, 8 Go...