
Nvidia Tegra 4 et 4i : tout savoir de leur architecture



Il y a quelques jours, nous avons eu l'opportunité de rencontrer une partie des équipes chargées de la conception des SoC Tegra et d'en apprendre plus sur leur architecture ainsi que sur les raisons des choix techniques qui ont été faits par Nvidia. CPU, GPU, sous-système mémoire, procédé de fabrication… vous saurez tout sur les Tegra 4 et Tegra 4i !
Le Tegra 4
Le premier SoC prévu par Nvidia cette année se nomme Tegra 4 et représente un successeur au Tegra 3. Sa structure est similaire mais il est basé sur des technologies remises au goût du jour.

Représentation artistique du die du Tegra 4, il s'agit d'un montage.
Tout comme le Tegra 3, il s'agit d'un SoC ARM quadcore. Il abandonne cependant les CPU Cortex-A9 au profit des récents Cortex-A15, nettement plus costauds et qui pourront atteindre 1.9 GHz dans un premier temps, contre 1.7 GHz pour le plus rapide des Tegra 3. Les Cortex-A15 améliorent sensiblement le taux d'IPC (Instructions Par Cycle) pour offrir un gain de performances conséquent, au prix cependant d'une consommation plus importante.
L'augmentation de celle-ci est contenue par Nvidia d'une part via l'utilisation du procédé de fabrication 28nm HLP de TSMC, optimisé pour réduire les courants de fuite, et d'autre part via la technologie vSMP (variable Symmetric MultiProcessing) également dénommée "core compagnon" ou "4+1". Elle consiste à donner le contrôle, au repos et en charge faible, à un 5ème core identique aux 4 principaux, un Cortex-A15 dans le cas présent, mais synthétisé dans l'optique d'une implémentation aussi économe en énergie que possible. En contrepartie, il est limité à 800 MHz.
Les 4 Cortex-A15 principaux disposent d'un cache L2 partagé de 2 Mo, contre 1 Mo sur le Tegra 3. Contrairement à ce dernier, le core compagnon n'y a cependant pas accès et dispose de son propre cache de 512 Ko.
Le GPU OpenGL ES 2.0, dénommé GeForce ULP, passe de 12 cores sur Tegra 3 à 72 cores sur Tegra 4. Nous reviendrons en détail sur ce GPU dans la suite de cet article, mais grossièrement cela revient à passer de 1 à 6 unités dédiées au traitement des triangles et de 2 à 4 pipelines de rendu des pixels avec une puissance de calcul triplée pour chaque pipeline. Tout cela couplé à une fréquence qui passe de 520 MHz à 672 MHz nous donne un GPU presque 8x plus puissant.

En plus d'une version BGA, non illustrée, le Tegra 4 sera proposé en version FCCSP 14x14mm. Nous avons mesuré une superficie de 90 mm² pour le die.
Pour alimenter un tel SoC, Nvidia a dû revoir sa copie au niveau du sous-système mémoire : le Tegra 4 passe enfin au double canal (2x 32-bit) et le contrôleur mémoire en lui-même a été amélioré pour un rendement supérieur et supporter la LPDDR3-1866 là où Tegra 3 se limitait à la LPDDR2-1066 ou à la DDR3L-1600.
Pour le Tegra 4, Nvidia a ajouté le support d'une sortie HDMI 4K ou UHD (3840x2160), autorise une résolution d'écran jusqu'à 3200x2000 (2048x1536 pour Tegra 3) et intégré un moteur vidéo revu, capable de soutenir des débits plus élevés.
Le Tegra 4i
Le petit frère du Tegra 4 ou le grand frère du Tegra 3, c'est selon, semble être légèrement en avance par rapport aux prévisions de Nvidia. Il s'agit du premier SoC de la société qui intègre directement un modem pour réduire les coûts et faciliter son intégration dans des designs compacts. Nvidia n'est pas peu fier d'indiquer que les premiers exemplaires de test de ce SoC sont sortis de d'usine il y a tout juste 2 semaines et sont déjà fonctionnels dans ses labos, raison pour laquelle la divulgation des détails le concernant a été quelque peu précipitée.

Représentation artistique du die du Tegra 4i, il s'agit d'un montage.
Le modem intégré est un i500 qui repose sur la technologie SDR : Software Defined Radio. Celle-ci repose sur l'utilisation de cores programmables, Nvidia parle de 8 cores à 1.3 GHz, pour supporter d'une manière flexible un maximum de standards avec un débit maximal de 150 mbps en 4G / LTE Cat4.
Le Tegra 4i se situe à mi-chemin entre le Tegra 3 et le Tegra 4. Fabriqué en 28nm HPM de TSMC, process optimisé pour faciliter la montée en fréquence, ce SoC quadcore reprend les cores CPU Cortex-A9, mais dans leur dernière révision, la r4, qui améliore quelque peu leur rendement. Couplés avec une fréquence maximale de 2.3 GHz, ils permettent un gain de performances significatif par rapport à Tegra 3, limité à 1.7 GHz et équipé en Cortex-A9 r2. La technologie vSMP reste de mise et un 5ème core Cortex-A9 r4, optimisé pour une faible consommation, prend le contrôle lorsque la puissance des 4 cores principaux n'est pas nécessaire.
Le GPU GeForce ULP intégré évolue lui aussi : il passe de 12 cores sur Tegra 3 à 60 cores sur Tegra 4i, ce qui correspond à 3 unités dédiées au traitement des triangles et à 2 pipelines de rendu des pixels avec une puissance de calcul multipliée par 6. Tout cela couplé à une fréquence qui passe de 520 MHz à 660 MHz nous donne un GPU presque 4x plus puissant au niveau du calcul de la géométrie et 7.5x plus puissant au niveau du calcul des pixels, même si leur débit maximal ne progresse presque pas.

Le Tegra 4i sera proposé en version PoP 12x12mm, à gauche avec le module mémoire attaché, au milieu sans, ainsi qu'en version FCCSP 12x12mm, à droite. Nous avons mesuré une superficie de 63 mm² pour le die.
Pour alimenter ce "petit" SoC, Nvidia a dû se contenter d'un accès mémoire simple canal (32-bit) mais le contrôleur mémoire reprend les petites améliorations du Tegra 4 et supporte la LPDDR3-2133 là où Tegra 3 se limitait à la LPDDR2-1066 ou à la DDR3L-1600.
Au niveau des sorties, le Tegra 4i doit se contenter du 1080p, que ce soit pour l'écran principal ou la sortie HDMI. Il reprend par contre le même moteur vidéo que le Tegra 4.
Le Cortex-A15
Le Cortex-A15 représente le dernier et le plus gros des cores basés sur l'architecture ARMv7. Il a été conçu dans l'optique d'augmenter le taux d'IPC (instruction per clock) pour se rapprocher petit à petit de ce dont sont capables les cores x86 autres que l'Atom actuel qu'il n'aura pas trop de mal à surpasser.

*Les caches L1 des Cortex-A9 et A7 sont configurables du 8 Ko à 64 Ko, 32 Ko étant la valeur par défaut.
Alors que le Cortex-A9 se contente de 5 unités d'exécution, le Cortex-A15 en dispose de 8 dont 2 dédiées au traitement des opérations vectorielles NEON, ce qui permet d'en traiter les vecteurs 128-bit en un seul cycle au lieu de 2. Les loads / stores disposent de leurs ports dédiés et les ALU ont été elles aussi dédoublées.

Pour alimenter la bête, le front-end a dû être musclé. Le Cortex-A15 double la bande passante vers le L1I et passe de 2 à 3 décodeurs d'instructions pour pouvoir en proposer un débit plus soutenu. Pour pouvoir profiter de toutes ses unités d'exécutions, il reste bien entendu un core Out of Order avec des évolutions importantes sur ce point. Le Reorder Buffer (ROB), qui représente la marge de manœuvre du moteur OoO, passe de 40 instructions pour le Cortex-A9 et Krait à 128, de quoi permettre au Cortex-A15 de trouver plus souvent des instructions prêtes à être exécutées. Par ailleurs, les instructions NEON peuvent dorénavant profiter elles aussi de l'exécution OoO. Seules certaines écritures en mémoire ne peuvent pas être réordonnancées, principalement parce que cela aurait trop d'impact sur le plan de la consommation.
Le pipeline des ALU passe de 9 étages à 15 étages entre le Cortex-A9 et le Cortex-A15 dont on peut penser que le nom a été choisi par ARM d'après cet aspect de leurs architectures. Pour réduire les effets négatifs de ce long pipeline, la prédiction de branchements joue un rôle important et elle a été largement améliorée pour éviter les erreurs très pénalisantes. Des algorithmes de prédiction plus évolués ont été mis en place et disposent d'une meilleure visibilité : le BTAC (Branch Target Address Cache) et le GHB (Global History Buffer) ont été étendus. Ils passent respectivement de 512 entrées à 4096 entrées et de 4096 prédicteurs à 16384 prédicteurs.
Enfin, le TLB (Transaction Look-aside Buffer) du cache L2 passe de 128 à 512 entrées pour permettre un maximum d'accès rapides et un prefetcher par Cortex-A15 fait son apparition dans le L2.
Au final, le Cortex-A15 est annoncé par ARM comme 40% plus performant que le Cortex-A9, en moyenne et à fréquence égale. En contrepartie, il est nettement plus gros et plus gourmand.
Le Cortex-A9 r4
Pour la plupart de ses cores, ARM propose généralement des révisions plus ou moins importantes, soit pour apporter des correctifs, soit pour apporter de petites améliorations à leur architecture. Le Cortex-A9 r4 représente une de ces évolutions.
Il a est principalement le fruit de plusieurs propositions faites par Nvidia à ARM pour adapter certains compromis au passage au 28nm et à des fréquences supérieures. Pour des raisons de licence, Nvidia n'avait pas la possibilité d'utiliser directement la base du Cortex-A9 et de la modifier à sa guise, ce qui explique qu'il s'agisse d'un core ARM accessible à tous. Nvidia estime cependant que ses efforts n'ont pas été sans intérêts puisqu'ils lui ont donné une avance de quelques mois sur la concurrence pour l'utilisation du Cortex-A9 r4.
Les améliorations concernent le front-end qui rejoint les spécificités du Cortex-A15 au niveau du TLB du L2, du BTAC et du GHB. Par ailleurs un prefetcher fait son apparition au niveau du cache L1D et, compte tenu de la taille relativement petite de celui-ci, dispose de son propre petit buffer pour éviter de cannibaliser le L1D.
Le Cortex-A9 r4 dispose donc d'un sous-système mémoire plus efficace et d'une prédiction de branchements renforcée. De quoi offrir jusqu'à 25% de gain à fréquence égale d'après Nvidia qui obtient ce score sous Bbench, 15% de mieux sous SPECint mais 0% de gain sous Dhrystone, un test qui ne stresse que les unités d'exécutions, ignorant le front-end et le sous-système mémoire.
Process : 28nm LP, HPL, HPM ou HP ?
Tous les procédés de fabrication d'une génération donnée, par exemple le 28 nanomètres, ne se valent pas, et les fondeurs en proposent en général plusieurs variantes. C'est le cas de TSMC qui décline le 28 nm en versions LP, HPL, HPM et HP, de la moins performante à la plus performante. Choisir le bon procédé est un aspect critique dans le développement d'une nouvelle puce particulièrement quand la consommation doit être parfaitement maîtrisée.
Quelle différence entre ces variantes ? Si nous acceptons de passer par une simplification grossière, nous pouvons voir les transistors comme des passoires : si les trous sont très petits, il y aura peu de fuites mais il faudra une pression plus importante pour qu'un flux d'eau conséquent la traverse au moment voulu, à l'inverse, si les trous sont plus gros, il y aura plus de fuites mais il faudra moins de pression pour qu'un flux d'eau la traverse.
En "langage transistor", cela revient à dire que plus un transistor est isolé vis-à-vis des courants de fuites (consommation statique), plus il demandera une tension élevée, et donc de l'énergie, pour changer d'état (consommation dynamique). A l'inverse, moins il est isolé, plus il souffrira de courants de fuite mais moins il demandera d'énergie pour commuter. Le 28nm LP représente le premier cas et le 28nm HP le second, les HPL et HPM se situant entre les deux.

Une grosse puce aura tendance à souffrir plus de la consommation statique, proportionnelle à sa surface et très variable, alors qu'une puce hautement cadencée souffrira d'une consommation dynamique qui explose. Pour produire une puce à l'efficacité énergétique élevée il n'y a donc pas de solution simple et suivant les objectifs visés, il faudra opter pour le meilleur compromis. Le LP est plus ou moins abandonné, il s'agissait du premier process 28nm proposé par TSMC, reposant sur une base proche de la technologie 40nm maison. Les 3 autres variantes font appel au High-K Metal Gate (HKMG) et proposent en général des compromis plus intéressants, certes avec des coûts de fabrication probablement plus élevés.
Pour le Tegra 4, Nvidia a opté pour le process 28nm HPL, d'une part parce qu'il était disponible plus tôt et d'autre part parce qu'il s'accorde mieux avec les "gros" cores Cortex-A15. Par contre, c'est le 28nm HPM, plus récent, qui entre en action pour le Tegra 4i et ses "petits" cores Cortex-A9 cadencés à très haute fréquence.
Dans les deux cas, une utilisation agressive du power gating est en place de manière à pouvoir isoler complètement les cores/caches qui ne sont pas utilisés, ce qui supprime alors presque totalement la consommation statique qui les concerne.
4 cores + 1
Depuis Tegra 3, Nvidia exploite une nouvelle technologie d'économie d'énergie dénommée vSMP, pour variable Symmetric MultiProcessing. Elle consiste à implémenter, sur un SoC quadcore, un cinquième core, identique sur le plan de l'architecture mais synthétisé de manière à donner la priorité à une faible consommation.
En exemple, ARM explique que sur le procédé de fabrication 40nm G de TSMC (variante haute performance qui a précédé au 28 nm HP), un Cortex-A9 dualcore conçu pour atteindre 2 GHz représente une surface de 6.9mm² alors qu'un même CPU conçu pour se limiter à 800 MHz se contente de 4.7mm² et d'une consommation 4x moindre. Sur Tegra 3, Nvidia avait profité d'un procédé de fabrication spécial de TSMC, le 40nm LPG, qui lui permettait de créer une zone de transistors G sur le process LP. De quoi réduire encore plus la consommation du 5ème core, Nvidia évoquant une différence de 10x.
Avec le 28nm, il n'est plus possible de combiner ces 2 types de transistors, mais des profils de transistors différents existent et sont utilisés lors du design des différents éléments du SoC. Nvidia parle toujours d'un gain de l'ordre de 10x au niveau de la consommation en faible charge grâce à cette approche. Il faut noter qu'avec les Tegra 4 et 4i, le gros cache L2 de 2 Mo est remplacé par un petit cache L2 de 512 Ko lorsque le 5ème core est actif, ce qui participe à réduire la consommation.
Ce core ne peut pas être exploité en même temps que les 4 cores principaux et fonctionne grossièrement comme un état inférieur de l'approche DVFS classique (Dynamic Voltage and Frequence Scaling). Quand un seul core est exploité et que le système DVFS demande d'abaisser la fréquence sous un certain seuil, les 4 cores principaux passent au repos total et le 5ème core est activé. Notons au sujet du DVFS que tous les cores principaux sont sur un même power plan et qu'ils fonctionnent donc toujours tous à la même fréquence et à la même tension.

Comment cette approche se compare-t-elle à d'autres solutions telles que big.LITTLE d'ARM ? Pour rappel, celle-ci consiste à associer des Cortex-A7 en nombre équivalent aux Cortex-A15 et à les exploiter lorsque la charge est faible. C'est ce que fait Samsung pour l'Exynos Octa. Selon Nvidia, si le concept est intéressant dans l'absolu, en pratique il revient à complexifier inutilement le design pour des gains de consommation qui seraient au final moindres que via l'ajout d'un seul core supplémentaire.
Dans ce cas, pourquoi ne pas utiliser un Cortex-A7, moins énergivore qu'un Cortex-A9, en tant que core compagnon ? Cette fois, Nvidia admet que la consommation pourrait être réduite dans certains cas, mais pas globalement, principalement pour 2 raisons. Tout d'abord, le Cortex-A7 serait insuffisant pour certaines tâches simples et les cores principaux devraient être actifs plus souvent. Ensuite, le système DVFS classique serait perturbé par la différence de performances importante à fréquence égale entre les 2 types de cores. Ainsi, des mécanismes plus évolués, peut-être contreproductifs sur le plan énergétique, devrait être mis en place pour éviter des allers-retours incessants entre ceux-ci.
Un argument que nous n'avons pas manqué de retourner à Nvidia par rapport au cache L2 plus petit du core compagnon des Tegra 4, certes avec un petit peu de mauvaise foi et d'ironie puisqu'il faut admettre qu'il représente une différence nettement moindre que 2 types de cores.
Une autre question pertinente à se poser est de se demander pourquoi ne pas avoir privilégié 2 Cortex-A15 à la place de 4 Cortex-A9 r4 pour le Tegra 4i. La majorité des applications Android et Windows RT sont très loin d'être massivement multihtreadées et il n'est pas illogique d'imaginer que 2 cores plus costauds auraient pu être un meilleur choix.
Sans nier que l'argument commercial 4 cores puisse être utile, Nvidia explique qu'il y a une raison technique derrière ce choix : passer de 2 à 4 cores est presque gratuit sur le plan de la consommation. Pourquoi ? Parce que ces cores supplémentaires ne sont en pratique exploitables qu'avec une fréquence et une tension inférieure, mais cela reste suffisant pour proposer des performances supérieures quand l'application est bien multithreadée. A l'inverse, passer de 2 Cortex-A9 à 2 Cortex-A15 a un impact très important sur la consommation.
Nvidia estime que son approche "4+1" représente le meilleur compromis actuel en termes de consommation au repos, de consommation en charge, de performances monothread et de performances multithread.
Cache L2 et contrôleur mémoire
Avec les Tegra 4 et 4i, Nvidia reprend l'implémentation standard d'ARM pour le cache L2. Celui-ci est ainsi partagé entre les 4 cores principaux et réparti dynamiquement entre eux suivant la charge. Plusieurs cores peuvent partager certaines données et un core peut se voir attribuer jusqu'à la totalité des 2 Mo du cache L2, ce qui est utile pour maximiser les performances monothread.
A l'inverse, Nvidia pointe du doigt Qualcomm et l'architecture Krait dont le cache L2 est en pratique fixé statiquement à 512 Ko par core, ce qui implique qui plus est le besoin de déplacer les données du L2 à chaque fois qu'un thread migre d'un core à l'autre.

Contrairement aux Tegra et à l'implémentation standard des cores ARM Cortex-A9/A15, Krait profite d'une architecture Asynchronous SMP qui permet à chaque core de fonctionner à une fréquence/tension indépendante pour optimiser la consommation à chaque instant suivant la charge de chaque core. En contrepartie, son cache L2 est donc moins efficace.
Nvidia est relativement conservateur concernant le nombre de canaux mémoires, respectivement 2 et 1 pour Tegra 4 et Tegra 4i, alors que le double canal se généralise chez la concurrence et qu'Apple pousse même jusqu'au quad canal avec l'A6x. Pour compenser, Nvidia se démarque par contre par le support de DDR3 très rapides, jusqu'à la LPDDR3-1866 pour le Tegra 4 et jusqu'à la LPDDR3-2133 pour le Tegra 4i. Reste que tous les intégrateurs n'utiliseront pas spécialement la mémoire la plus rapide possible, notamment s'ils désirent limiter la consommation.
Difficile cependant de comparer le niveau d'efficacité des différents contrôleurs mémoire. Nvidia indique avoir progressé sur ce point avec les Tegra 4, notamment grâce à des buffers allongés pour maximiser le rendement, par exemple en facilitant le groupement des accès vers des zones mémoire proches, ce qui profite autant aux performances qu'à la consommation.
Ce contrôleur mémoire reste bien entendu capable de favoriser certains accès plus urgents, notamment concernant le GPU, et de réduire sa fréquence et celle de la mémoire lorsqu'il détecte que la latence et/ou le débit ne sont plus critiques. Calibrer tout cela et obtenir le meilleur compromis entre consommation et performance demande pas mal d'expérience et se fait petit à petit au fil des évolutions des SoC.
Enfin, certains gros accès, typiquement liés à l'affichage des images, se font à intervalle régulière. Via des timers, le GPU est capable d'informer le contrôleur mémoire de la cadence de ces accès de manière à ce que ce dernier puisse anticiper agressivement les périodes de repos et les périodes de burst pour réduire la consommation et maximiser les débits.
Le GPU GeForce ULP
Alors que beaucoup pourraient penser que, Nvidia oblige, Tegra 3 dispose d'un GPU puissant et évolué, il n'en est rien. Le GeForce ULP de Tegra 3 commence en effet à faire pâle figure par rapport à ce que propose la concurrence, que ce soit ARM avec les Mali 600, Qualcomm avec les Adreno 300 ou encore ImgTech avec les PowerVR Series5XT. Tous proposent des configurations nettement plus musclées et des architectures plus évoluées pour supporter les API modernes.
Avec les GeForce ULP de Tegra 4 et de Tegra 4i, Nvidia s'est enfin attaché à faire bouger les choses, tout du moins sur le premier point : la puissance brute. L'architecture conserve par contre l'ancien pipeline de rendu fixe, Nvidia estimant que passer sur un modèle unifié plus moderne serait contre-productif à cause d'un coût important en terme de consommation.
L'architecture GeForce ULP est souvent décrite comme dérivée des GeForce 6/7, mais ce n'est pas correct. En réalité elle n'est dérivée d'aucune architecture GeForce précédente, celles-ci n'étant pas adaptées aux économies d'énergie. Pour masquer la latence du texturing, l'architecture de leurs moteurs de rendu des pixels était basée sur un pipeline extrêmement long (type buffer FIFO de 256 étages), très gourmand et peu flexible vis-à-vis de l'allocation des registres utilisés pour le calcul des pixels shaders. A l'époque, ATI avait choisi une autre voie, intermédiaire entre les architectures non-unifiées de Nvidia et les architecture unifiées modernes. Ainsi, s'il fallait comparer le GeForce ULP à une architecture GPU classique, c'est probablement celle des Radeon X1900 qui en serait la plus proche.
Voici à quoi ressemble l'architecture des GeForce ULP présents dans les Tegra 3, Tegra 4i et Tegra 4 :
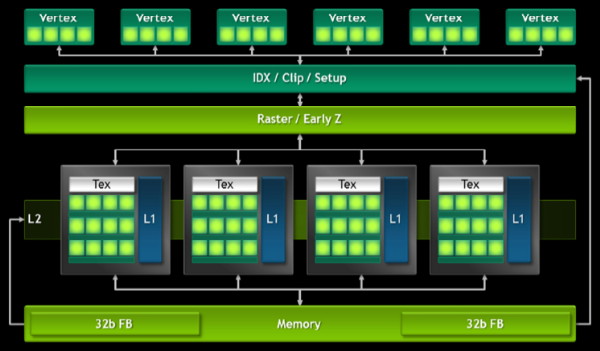
| [ Tegra 3 ] [ Tegra 4i ] [ Tegra 4 ] |
Nous pouvons observer :
- un certain nombre de blocs de traitement des vertices
- un bloc pour le setup et le clipping
- un bloc pour le raster engine et l'early-z
- un certain nombre de blocs dédiés au calcul des pixels
Et des configurations de type :
- Tegra 3 : 1 vertex engine + 2 pixel pipelines (x1 pixel shader)
- Tegra 4i : 3 vertex engines + 2 pixel pipelines (x6 pixel shaders)
- Tegra 4 : 6 vertex engines + 4 pixel pipelines (x3 pixel shaders)
Chaque bloc de traitement des vertices (nommés Vertex Processing Engines ou VPE) inclut une unité de calcul vec4 capable de traiter des opérations MAD FP32 en un cycle, elles correspondent selon Nvidia à "4 cores". Pour Tegra 4/4i, chaque VPE dispose d'un VBO (Vertex Buffer Object) de 16 Ko pour ne pas avoir à lire en mémoire plusieurs fois chaque vertex (ils sont en général partagés par plusieurs triangles), et Nvidia annonce des performances par cycle en hausse de 50% pour rapport au VPE de Tegra 3.
Le setup se charge d'assembler les primitives, en général des triangles, à partir des vertices traités. Si celles-ci se trouvent hors du champ de vision ou tournent le dos à la caméra, elles sont éjectées du rendu.
Le raster engine se charge de découper les primitives en pixels et est capable d'en générer 8 par cycle accompagnés de leur valeur Z qui représente leur profondeur dans la scène. Son débit est nettement plus élevé que celui du calcul des pixels qui se limite à 2 ou 4 pixels par cycle. Quel intérêt ? L'Early-Z, qui consiste à détecter, avant son rendu, si un pixel est visible ou masqué, auquel cas il sera éjecté du rendu. L'unité d'Early-Z des GeForce ULP est capable de tester et d'éjecter jusqu'à 8 pixels par cycle, ce qui explique le débit de son raster engine.
Pour les pixels qui en principe seront visibles, entrent alors en scène les pixel pipelines. Chacune d'entre elles est bâtie autour d'une unique unité de texturing, l'élément le plus gourmand d'un GPU, qui dispose d'un cache L1 indéterminé (et non représenté sur le schéma) connecté à un cache L2 global à l'ensemble des unités de texturing du GPU. Celui-ci est de 16 Ko pour Tegra 4 et Tegra 4i.
Chaque pixel pipeline dispose d'un certain nombre d'unités de traitement des pixels shaders, 1 pour Tegra 3, 3 pour Tegra 4 et 6 pour Tegra 4i. Chacune est composée d'une unité vectorielle de type VLIW4 (= "4 cores" pour Nvidia) et d'une MFU (Multi-Function Unit) chargée des opérations complexes (log, exp, sin, cos, rcp, rsq, mov…). Les ports pour les alimenter en registres étant limités, il n'est pas possible d'exploiter la MFU quand l'unité VLIW4 traite 4 MAD, mais bien quand elle traite des produits scalaires. Nvidia donne quelques exemples de ce qui est possible :
- 4x MAD
- 2x DP2A + MFU
- 1x DP3A + 1xMAD + MFU
- 1x DP2A + 2xMAD + MFU
- 1x DP4 + MFU
La latence liée aux opérations de texturing et autres accès mémoire est masquée via la traitement de nombreux pixels ("threads") et l'utilisation d'un fichier registre conséquent dans lequel restent au repos ceux qui sont en attente de la finalisation d'une opération à latence élevée. Ainsi, moins un pixel shader exige de registres, plus le nombre de pixels qui peuvent tenir dans le fichier registre physique est élevé et mieux la latence est masquée. A l'inverse, si le pixel shader est complexe et demande beaucoup de registres, la latence est moins bien masquée et le GPU peut perdre de nombreux cycles à attendre un résultat. Il revient au compilateur de faire le meilleur compromis, quitte dans certains cas, par exemple, à dédoubler certaines opérations dans un pixel shader pour ne pas avoir à en retenir le résultat dans un registre. Nvidia ne communique pas sur la taille du fichier registre des GeForce ULP, mais nous pouvons supposer qu'il est équivalent à au moins 2048 registres 20-bit par pixel pipeline.
Contrairement aux GPU de bureau, les GeForce ULP ne disposent pas de ROP distincts chargés d'écrire/lire le framebuffer et de réaliser les opérations de mélange en cas de pixels transparents. Toutes ces opérations sont donc traitées par les unités de pixel shaders, probablement assistées par quelques unités fixes. Un pixel cache de 16 Ko (cache L1 sur le schéma) pour l'ensemble du GPU permet de limiter les accès mémoire et chaque pixel pipeline peut débiter 1 pixel par cycle. Sur le plan des fonctionnalités, notez que Nvidia a ajouté à ce niveau le support de l'antialiasing multisample 2x/4x avec compression. Il remplace le CSAA supporté sur Tegra 3.
Nvidia indique qu'avec une architecture fixe optimisée en profondeur, quelques compromis sur la précision de calcul et une fréquence relativement élevée, le GPU de Tegra 4 peut lutter contre des GPU concurrents du moment bien plus gros. Ces chiffres nous ont été fournis par Nvidia et nous avons pu les vérifier dans le cas des performances : (superficie normalisée en 28nm / performances GLBench 2.5 @ fréquence GPU)
- Tegra 4 et GeForce ULP : 10.5 mm² / 54 fps @ 672 MHz
- Snapdragon S4 Pro (APQ8064) et Adreno 320 : 19.2 mm² / 30 fps @ 400 MHz
- Exynos Dual et Mali 604 : 18.5 mm² / 29 fps @ 533 MHz
- A5x et PowerVR SGX543MP4 : 26.2 mm² / 25 fps @ 250 MHz
- A6x et PowerVR SGX554MP4 : 37.3 mm² / 52 fps @ 280 MHz
Le plein de cores, c'est génial ?
Notez que Nvidia distingue ses GeForce ULP par un nombre de cores et estime que chaque unité de calcul MAD (multiplication + addition) représente un core. Alors que nous ne sommes déjà pas fans de cette vision des choses dans le cas des GeForce de bureau, cela devient clairement abusif dans le cas d'un GPU au pipeline fixe dont les unités de calcul sont qui plus est de type vectoriel VLIW4.
Par ailleurs, et cela n'a probablement pas échappé à Nvidia, cela sème la confusion par rapport aux GPU concurrents qui sont implémentés par blocs fondamentaux. Ainsi un core PowerVR correspond à 16 ou 32 MAD + tous les autres éléments nécessaires au calcul des pixels, nous sommes donc dans la même logique que pour des cores CPU. Si tout le monde optait pour la même définition d'un core que Nvidia on assisterait à une explosion de leur nombre pour l'ensemble des GPU (jusqu'à 128 pour le PowerVR SGX 554MP4 et pour l'Adreno 330), sans compter qu'il est possible de faire de même avec les CPU et leurs unités vectorielles.
Nvidia ne changera probablement pas sa manière de compter, tant sa communication est orientée autour de ce nombre de cores. Il pourrait cependant être utile de nommer les GeForce ULP de manière à les différencier en faisant abstraction du nombre de cores (par exemple : GeForce ULP 320, GeForce ULP 430 et GeForce ULP 450).
Pas de FP32, pas de DirectX 9_3, pas d'OpenGL ES 3.0, pas d'OpenCL, c'est grave ?
Pour le calcul des pixels, contrairement à la concurrence, Nvidia a décidé de faire l'impasse sur la précision FP32 (highp) devenue le standard. Tout comme les précédents Tegra, les Tegra 4 se limitent ainsi au FP20. Ce format peut paraître étrange au premier abord, mais il permet de profiter d'une précision supérieure au FP16 (mediump) tout en facilitant la gestion du format lowp d'OpenGL ES. Ce dernier se limite à une précision de 10-bit (FX10) et permettra sur GeForce ULP de disposer de plus de registres, et dans certains cas, de mieux alimenter les unités de calcul, même si en elles-mêmes elles ne tourneront pas plus vite.
Le choix du FP20 permet de simplifier les unités de calcul et de réduire significativement la consommation. Sur la génération actuelle et avec des pixel shaders trop courts pour que la précision ne pose de problème (via propagation de l'erreur), le choix de Nvidia ressemble à un très bon compromis.
Cela va-t-il poser problème avec Tegra 4 ? Non, selon Nvidia qui démontre son point de vue via une simulation du rendu de plusieurs jeux PC simples en FP20, ce qui est plutôt ironique quand on se souvient qu'il y a quelques années, Nvidia nous expliquait tout le mal qu'il pensait du FP24 des Radeon par rapport au FP32/FP16 des GeForce. La différence est presque nulle sur les exemples choisis par Nvidia, mais il serait bien entendu possible d'en trouver d'autres où cela pose un problème ou réduit sensiblement la qualité.
Il est difficile de prévoir ce que feront exactement les développeurs, ce qui dépendra en partie du succès commercial de chaque solution, mais selon nos informations, ils vont privilégier OpenGL ES 2.0 pour quelques temps encore et ils ont l'habitude de travailler en précision réduite sous cette API. La précision limitée au FP20 des Tegra 4 ne sera ainsi probablement pas un gros problème, même si le support du FP32 aurait été plus que bienvenu, ne serait-ce que pour débloquer l'accès à OpenGL ES 3.0 et au niveau 9_3 de DirectX.
Car en dehors de la précision de calcul, Nvidia en a ajouté toutes les fonctions ou presque dans Tegra 4/4i :
- Z-Buffer 24-bit (20-bit auparavant)
- Textures 4K x 4K
- Filtrage des textures HDR FP16
- Filtrage des ombres (Percentage Closer Filtering)
- Formats sRGB
- -Tests d'occultation
- Multiple Render Targets (MRT x4)
- Geometry Instancing
- …
Si supporter toutes ces fonctionnalités peut se faire assez facilement sous OpenGL ES 2.0, ce n'est malheureusement pas le cas sous DirectX de Windows RT, beaucoup plus rigide et qui propose peu de fonctions optionnelles : c'est tout ou rien. Comme nous l'avions expliqué dans un article dédié les GPU des Tegra sont limités au niveau 9_1, le plus faible de l'API et cela ne change pas avec Tegra 4.
Nvidia reconnait le problème et indique qu'une solution éventuelle ne pourrait venir que de Microsoft, par exemple si ce dernier décidait de ne plus exiger la précision FP32 pour le niveau 9_3. Rappelons que ce niveau autorise de nombreux formats de calcul en précision réduite (16-bit, 12-bit et 10-bit) et qu'un GPU tel que celui de Tegra 4/4i pourrait ainsi fonctionner en 9_3 sans "tricher". L'accès y est cependant conditionné au support du FP32, même s'il n'est pas utilisé.
Notez que si Microsoft a choisi le Tegra 3 pour Surface RT, ce n'est bien entendu pas pour son support complet de DirectX, mais probablement par défaut parce que Nvidia était seul capable de fournir des pilotes fiables dans les temps. Cette Surface RT ayant dès lors défini la plateforme de référence, il est peu probable que Microsoft estime crucial de revoir son API pour faciliter le support d'un niveau supérieur.
Enfin, avec un pipeline fixe et une précision FP20, Nvidia ne peut bien entendu pas supporter OpenCL.
Pas de TBDR ou de TBR, c'est grave ?
Comme les GPU de bureau AMD et Nvidia, le GeForce ULP travaille en mode de rendu direct, c'est-à-dire que les triangles sont rendus complètement les uns après les autres.
A l'inverse, les GPU PowerVR d'ImgTech travaillent en mode TBDR (Tile-Based Deferred Rendering). L'ensemble des primitives (les triangles) sont passées en revue lors d'une première passe pour déterminer leur position. Le rendu se fait ensuite par petites zones, les tiles qui tiennent dans un buffer dédié, en se servant de la première passe pour savoir quel pixel sera visible. Cette approche permet d'éviter de gaspiller de la puissance de calcul et de la bande passante mémoire en calculant et écrivant inutilement des pixels masqués. Notez qu'ImgTech en profite souvent pour bidouiller ses chiffres et annoncer des fillrate "équivalents" à ceux des architectures qui gaspilleraient plus de ressources.
Les GPU Adreno et Mali font appel au Tile-Based Rendering (TBR à ne pas confondre avec le TBDR) également nommé binning pour éviter la confusion avec la méthode des GPU PowerVR. La première passe de traitement de la géométrie est similaire, mais elle n'est utilisée que pour déterminer dans quelle(s) tile(s) chaque primitive est visible. Le rendu se fait ensuite en mode direct mais tile par tile. Celles-ci étant suffisamment petites que pour tenir dans un buffer dédié, toutes les opérations intermédiaires d'écriture et de mélange de pixels ne consomment pas de bande passante mémoire.
Le TBR et le TBDR peuvent cependant souffrir plus avec l'augmentation de la complexité de la géométrie et certaines techniques de rendu. Avec les GPU Adreno 300, Qualcomm a introduit le FlexRender, qui consiste à permettre au GPU de travailler soit en TBR soit en rendu direct pour utiliser la méthode la plus efficace. Le pilote essaye de déterminer la meilleure solution, mais les développeurs ont la possibilité de lui indiquer la marche à suivre.
Le GeForce ULP est-il fortement désavantagé en étant limité au rendu direct ? Nous ne le pensons pas. Il faut dire qu'avec l'expérience de Nvidia au niveau de l'efficacité de ses GPU (culling, cliping, early-z, compression, caches) et les bonnes pratiques en général répandues chez les développeurs, l'overdraw, soit la quantité de pixels qui se superposent et sont donc écrits plusieurs fois en mémoire, n'est pas dramatique. Les GeForce ULP consomment probablement un peu plus de bande passante mémoire pour l'écriture dans le framebuffer, mais d'un autre côté les GPU TDBR et TBR font face à plusieurs challenges avec certaines techniques de rendu, ce qui y limite leur efficacité.
Processeur vidéo et Chimera
Le moteur vidéo de Tegra 4/4i a été mis à jour par rapport à Tegra 3. Ne rêvez pas, il est encore trop tôt pour supporter le tout frais h.265. La mise à jour principale est liée au débit maximal pour le décodage qui, en h.264, passe de 40 mbps à 62.5 mbps, le débit nécessaire pour supporter la lecture des Blu-ray 3D.
Voici les formats supportés en décodage :
- H.264 HP/MP/BP 62.5Mbps : 4Kx2K @24p, 1440p @30p, 1080p @60p
- VC1 AP/MP/SP 40Mbps : 1080p @60i/30p
- MPEG4 SP 10Mbps : 1080p @30p
- WebM VP8 60Mbps : 1080p @60p, 1440p @30p
- MPEG-2 MP 80Mbps : 1080p @60i/60p
Et en encodage :
- H.264 (BP/MP/HP) 50Mbps : 1080p @60p, 1440p @30p
- MPEG4 SP 10Mbps : 1080p @30p
- VP8 50Mbps : 1080p @60p, 1440p @30p
Le processeur d'images (ISP) de Tegra 4/4i a lui aussi été mis à jour pour pouvoir prendre part à ce que Nvidia appelle la Chimera Computational Photography Architecture. Grossièrement il s'agit d'un ensemble d'API qui permet d'exploiter le GPU, le CPU et l'ISP main dans la main pour améliorer l'aspect prise de vue, que ce soit pour des photos ou des vidéos.
L'avantage principal concerne la puissance de traitement qui se trouve démultipliée par rapport à certaines solutions plus basiques. Cette puissance supplémentaire permet d'accélérer le traitement du HDR à tel point qu'il devient possible dans ce mode de filmer en 1080p, de faire des panoramas, du burst etc. La qualité est également en hausse grâce à un intervalle qui se réduit entre les 2 clichés avec exposition différente qui permettent de créer chaque image HDR.

Les API de Chimera permettent aux développeurs d'appliquer des opérations (kernels) autant dans le domaine de Bayer (données brutes du capteur) que dans le domaine YUV (après conversion par l'ISP). Suivant leur type, ces kernels pourront tourner soit sur le GPU, soit sur le CPU. Les possibilités sont nombreuses, et si Nvidia se concentre au départ sur le HDR, c'est qu'il permet de répondre à un besoin en compensant les faiblesses des capteurs compacts et surtout représente un argument commercial important, d'autant plus que la concurrence est aussi sur le sujet.
Il est intéressant d'observer que Nvidia fait ici du GPU computing "à l'ancienne" (type BrookGPU), c'est-à-dire sans disposer d'une architecture GPU adaptée et encore moins d'un bus cohérent entre le CPU et le GPU. Un bricolage qui fonctionne puisque dans un exemple concernant le HDR, Nvidia nous explique qu'en pratique :
- les vertex processing engines et le raster engine s'occupent de l'indexation
- les unités de textures samplent les images en profitant de leur cache pour consommer moins de bande passante mémoire
- les unites de pixel shaders s'occupent du mélange et de la reconstruction
Tableau récapitulatif des SoC
Nous avons récapitulé les spécifications principales de plusieurs SoC à venir ou déjà présents sur le marché afin de vous permettre de situer Tegra 4 et Tegra 4i par rapport à la compétition. Voici les SoC que nous avons listés :
- Apple A6
- Apple A6x
- Intel Z2460
- Intel Z2760
- Intel Z2580
- MediaTek MT6589
- Nvidia Tegra 3
- Nvidia Tegra 4i
- Nvidia Tegra 4
- Qualcomm Snapdragon S4 Pro
- Qualcomm Snapdragon 600
- Qualcomm Snapdragon 800
- Samsung Exynos 5 Dual
- Samsung Exynos 5 Octa
- ST-Ericsson NovaThor L8580

Notez que les débits présentés pour les GPU ne représentent que des valeurs brutes et que les différentes architectures n'ont pas le même rendement par rapport à ceux-ci.
Conclusion
Arrivés au bout de cette analyse "presque" complète des Tegra 4 et Tegra 4i (nous vous avons épargné les détails concernant le modem i500), force est de constater qu'ils semblent plus que bien armés face aux solutions actuelles ou annoncées, quoi qu'en disent certains concurrents.
Nous pensons notamment aux Snapdragon et aux déclarations plutôt agressives d'Anand Chandrasekher , Chief Marketing Office de Qualcomm (et ancien SVP et General Manager de la division Ultra Mobility d'Intel) qui indique que le Tegra 4 ne fait que revenir au niveau de ses SoC actuels, que le Snapdragon 600 fera mieux et que le Snapdragon 800 mettra tout le monde d'accord. Compte tenu des performances du Snapdragon S4 Pro et de notre compréhension des évolutions à venir, tout cela semble fantaisiste et en réalité, sur le plan des performances, le Tegra 4 devrait résister au Snapdragon 800.
Pour le déloger de la première place, il faudra probablement attendre le Snapdragon haut de gamme suivant, le futur A7x d'Apple ou encore le futur SoC Intel basé sur l'architecture Atom Silvermont et fabriqué en 22nm. Reste bien entendu à voir quand exactement Nvidia pourra livrer le Tegra 4 en volume, il est attendu pour cet été, et quelle sera sa consommation réelle dans des tâches lourdes. A ce sujet, Nvidia ne communique aujourd'hui que sur des situations de charge faible ou à très basse fréquence, pour éviter de confirmer une évidence : Tegra 4 consommera plus que Tegra 3 en pleine charge. La question est de savoir dans quelles proportions et quelles seront les spécifications exactes que Nvidia pourra proposer pour équiper une tablette compacte voire un smartphone.

Les plateformes de référence Tegra 4 et Tegra 4i, nom de code Phoenix, sont prêtes.
Attendu pour la fin de l'année, le Tegra 4i représente le SoC au plus gros potentiel pour Nvidia. Grâce à une consommation qui devrait être modérée, à un bon niveau de performances et à un modem 4G/LTE intégré, plus de portes vont enfin s'ouvrir pour Nvidia dans le monde des smartphones. Cela ne veut pour autant pas dire que le succès est assuré puisque cette fois la concurrence sera rude à tous les niveaux, avec par exemple des SoC plus performants ou plus économes, et Nvidia devra convaincre en pratique par rapport au compromis, plutôt intéressant sur le papier, que représente Tegra 4i.
Enfin, sur le plan graphique et plus particulièrement du support des jeux vidéo, Nvidia compte sur son expérience au niveau des pilotes et de la collaboration avec les développeurs pour garder une longueur d'avance, malgré un niveau de fonctionnalité quelque peu en retrait par rapport à la concurrence. Dans certains jeux, les SoC Tegra 4/4i profiteront ainsi probablement d'effets graphiques exclusifs comme c'est déjà le cas dans quelques titres actuels. Nvidia propose également différents outils pour faciliter la bonne exploitation de ses SoC, Tegra Profiler, Nsight Tegra et PerfHUD ES… qui sera bientôt "power aware" pour permettre aux développeurs d'optimiser et de contrôler l'aspect consommation et non plus simplement les performances.




Contenus relatifs
- [+] 25/01: AMD annonce la restructuration de R...
- [+] 28/09: Nvidia annonce le SoC Xavier avec G...
- [+] 03/05: Accord de licence Nvidia-Samsung
- [+] 07/01: CES: Drive PX 2: Tegra et Pascal au...
- [+] 06/05: Nvidia va arrêter les modems Icera
- [+] 04/03: GDC: Nvidia annonce une console Shi...
- [+] 05/01: CES: Nvidia Tegra X1: Maxwell + Cor...
- [+] 25/03: GTC: Tegra: Kit Jetson TK1, SoC Eri...
- [+] 06/01: Nvidia Tegra K1 et son GPU Kepler :...
- [+] 06/01: CES: Nvidia annonce Tegra K1, avec ...