
ARM Cortex A7 et big.LITTLE : le silicium noir
Publié le 24/10/2011 par Damien Triolet




Lors de l’AMD Fusion Developer Summit qui s’est tenu il y a quelques mois, un invité avait fait sensation : Jem Davies, Vice-Président chez ARM, en charge de la technologie pour la division Media Processing. Sa présence n’était cependant pas liée à l’annonce de l’utilisation de l’architecture ARM par AMD, comme certains avaient pu le supposer. Jem Davies a la lourde responsabilité de s’assurer qu’ARM dispose des "bonnes technologies" dans le futur et partage à ce titre la vision d’AMD pour le calcul hétérogène. C’était la raison de sa présence.
AMD, et l’ensemble de l’écosystème PC, a besoin du calcul hétérogène pour continuer la course aux performances sans faire exploser la taille des puces et la consommation. La célèbre loi de Moore prédit que la complexité des processeurs, soit leur nombre de transistors, double tous les 2 ans à coûts plus ou moins constants. Une prédiction qui fait office d’horizon pour une grande partie de l’industrie. Grossièrement, tous les deux ans, un nouveau procédé de fabrication permet de doubler la densité des transistors et donc de fabriquer un processeur deux fois plus complexe pour une taille identique, sachant que cette dernière est un paramètre important dans son coût de fabrication. AMD, Intel et Nvida profitent de ces évolutions pour faire progresser les performances des CPU et des GPU.
D’une manière anticipée par rapport au monde PC traditionnel, ARM fait cependant face à une contrainte énergétique qui met à mal ce modèle. La contrainte énergétique est en effet la première des priorités pour cette architecture tout terrain qui se retrouve dans la majorité des smartphones et des tablettes. Or si chaque évolution des procédés de fabrication (45nm -> 32nm -> 22nm…) permet de réduire de moitié la taille des transistors, leur consommation ne se réduit pas dans les mêmes proportions.

Jem Davies nous présentait alors un exemple grossier et approximatif entre le 45nm et le 22nm : en 4 ou 6 ans suivant l’accès aux technologies, un processeur identique va comme prévu voir sa taille divisée par 4, sa fréquence maximale progresser de 60%, mais sa consommation reste identique. Certes il y a un gain appréciable de 60%, mais la limite de consommation représente surtout une opportunité manquée d’utiliser le procédé de fabrication plus avancé, et l’espace ainsi gagné, pour mettre au point une puce plus complexe et nettement plus performante.
Les CPU et les GPU d’AMD, Intel et Nvidia font également face à cette problématique mais dans une moindre mesure, suivant qu’ils visent le marché de bureau ou mobile, leurs architectures laissant encore place à de nombreuses optimisations énergétiques. A moyen terme, la multiplication de cores identiques posera néanmoins problème, autant en terme de rendement qu’en terme de consommation.
Selon Jem Davis, la solution est le recours au calcul hétérogène ainsi qu’au silicium noir qu’il faut ici comprendre comme silicium inactif. L’idée générale, au-delà des unités fixes dédiées à des tâches bien précises telles que le décodage des vidéos, est de profiter de l’évolution des procédés de fabrication pour implémenter différents types de cores, tout en gardant en tête que l’enveloppe thermique ne permettra pas de tous les alimenter. Ces types de cores doivent ainsi être adaptés à certains profils de tâches, être exploités pour traiter celles-ci et rester dans l’ombre le reste du temps.
C’est du même principe qu’est parti Nvidia pour Kal-El, nom de code du SoC qui devrait s’appeler Tegra 3. En plus de 4 cores ARM Cortex A9 principaux, ce dernier disposera d’un cinquième core Cortex A9, construit à partir de transistors moins performants en terme de fréquence mais optimisés pour réduire les courants de fuite et donc la consommation. Suivant les tâches à accomplir soit ce core compagnon, soit les cores principaux seront actifs.
ARM entend bien entendu aller beaucoup plus loin que ça, ce qui nous amène aux nouveautés qui viennent d’être dévoilées et qui représentent un premier pas vers cette stratégie d’architecture hétérogène et de silicium noir. Un nouveau core vient ainsi d’être présenté : le Cortex A7. Contrairement à ce que son nom indique, il ne s’agit pas du core qui a précédé les Cortex A8 (utilisé dans de nombreux SoC tels que l’Apple A4) et A9 (Tegra 2 & 3, Apple A5, etc.), mais bien d’un nouveau core, petit frère du Cortex A15. Pour rappel, ce dernier représente une évolution majeure pour ARM en terme de performances.
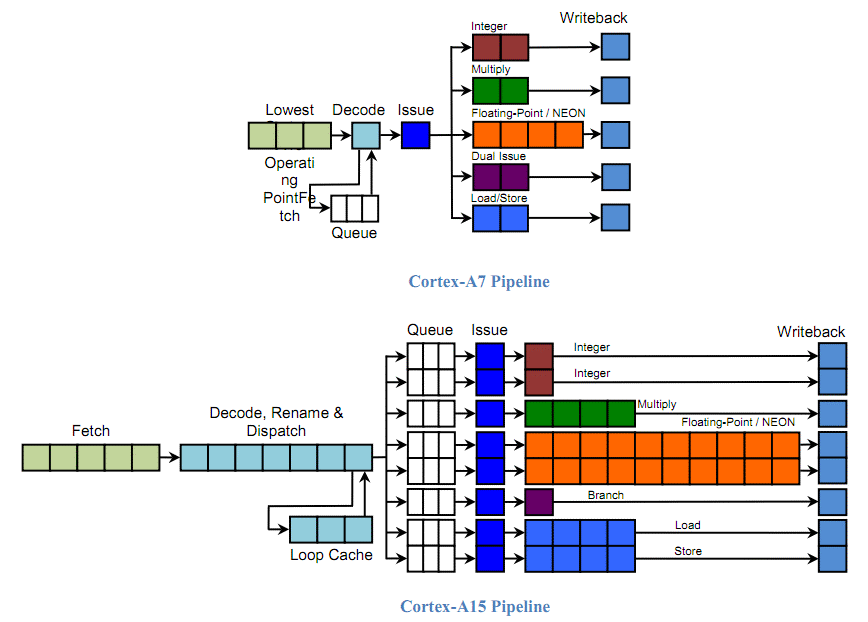
Les Cortex A15 et A7 reposent sur une même architecture (ARM A7a) et exécutent toutes les instructions d’une manière consistante. Tous les deux peuvent être implémentés seuls ou jusqu’en versions quadcores, avec un cache L2. C’est au niveau de leur microarchitecture qu’ils diffèrent, le Cortex A15 ayant été optimisé pour les performances, out-of-order et long pipeline, alors que le Cortex A7 a été optimisé pour le rendement énergétique, in-order et pipeline court.

Si le Cortex A7 peut être exploité pour mettre au point un SoC bon marché et peu énergivore, représentant alors une mise à jour intéressante du Cortex A8 (moins performant et plus gourmand), il prend tout son sens dans l’architecture dénommée big.LITTLE qui consistera à implémenter des Cortex A7 ainsi que des Cortex A15 dans un même SoC et d’exécuter les tâches, suivant leur lourdeur ou leur priorité, sur l’un ou l’autre type de cores.

Contrairement à l’approche de Nvidia avec Kal-El, la cohérence de l’ensemble ne se fera pas au niveau d’un cache L2 partagé, ARM précisant à ce sujet que le cache L2 représente un potentiel d’économies d’énergies très élevé et qu’il est plus utile d’adapter sa structure à chaque type de cores. Typiquement, chaque groupe des Cortex A7 ou A15 disposera de son propre cache L2 et la cohérence sera assurée par une interconnexion robuste, prévue pour supporter les cas les plus complexes.
Pour exploiter tous ces cores, deux options sont possibles. Le modèle migration de tâches consiste à exploiter soit les Cortex A15, soit les Cortex A7, mais jamais les deux en même temps, en passant des uns aux autres à la manière d’un changement de fréquence (modèle DVFS, Dynamic Voltage and Frequency Scaling). Quand le système va arriver au point de performances le plus élevé défini pour les Cortex A7, une migration de tâche va pouvoir être invoquée pour déplacer le traitement de l’OS et des applications vers les Cortex A15.

Cette migration se fait en moins de 20.000 cycles selon ARM, ce qui représente 20µs à 1 GHz. Le SoC n'est cependant pas complètement inaccessible pendant ces 20µs : pendant une partie de la migration, les tâches continuent à être exécutées sur les cores d’origine. Un changement d'état qui semble ainsi nettement plus rapide que celui de 2ms annoncé par Nvidia pour Kal-El.
Dans ce mode, ARM conseille d’implémenter le même nombre de cores Cortex A15 que de Cortex A7, de manière à simplifier tout l’aspect logiciel. ARM fourni à ce sujet un switcher logiciel qui intègre le système de migration de tâche et masque les petites différences entre les deux architectures. Il peut être utilisé dès aujourd’hui tel quel (en profitant de la virtualisation) ou, mieux, être intégré dans les systèmes d’exploitation.
La seconde option est de recourir au modèle MP, ou multiprocessing hétérogène, qui consiste à utiliser simultanément les Cortex A7 et A15. L’intérêt est alors de diriger chaque tâche vers le core le plus adapté, soit vers les Cortex A7 s’il s’agit d’une tâche simple ou non prioritaire, soit vers les Cortex A15 si plus de puissance est utile, chaque type de cores restant au repos complet s’il n’est pas sollicité. ARM ne décrit cependant pas le mécanisme qui dirige les tâches vers l’un ou l’autre groupe de cores et nous supposons ici que logiciels et systèmes d’exploitation doivent être adaptés.

Ce n’est pas tout puisque la couche d’interconnexion est prévue pour recevoir également le GPU Mali T604 qui supporte… OpenCL 1.2 ! Bien entendu, exploiter simultanément des Cortex A7, des Cortex A15 et un GPU Mali T604 quadcore à travers OpenCL ne pourra se faire que si le TDP n’est pas un facteur limitant. Dans les autres cas le mécanisme chargé de diriger les tâches devra prendre en compte de nombreux paramètres liés à la consommation et arriver à trancher entre toutes les options qui se présentent à lui : par exemple, pour une tâche donnée, vaudra-t-il mieux utiliser 4 Cortex A15 ou 2 Cortex A7 + le Mali T604 en OpenCL ?
Si AMD et ARM ont tous les deux besoins du calcul hétérogène, ils font également face au même défi : parvenir à l’exploiter efficacement, que ce soit sur le plan énergétique ou des performances. Reste ensuite à convaincre leurs partenaires de faire de même, principalement pour les systèmes d’exploitation. ARM dispose ici d'un avantage de taille : sa présence dans des écosystèmes logiciels qui évoluent très vite là où AMD doit faire avec la lourdeur de l’écosystème x86…

A lire également




Vos réactions
Contenus relatifs
- [+] 26/04: Jim Keller rejoint... Intel !
- [+] 14/03: Des failles de sécurité spécifiques...
- [+] 11/01: CES: Un écran OLED 4K 21.6 pouces c...
- [+] 11/01: CES: L'Exynos 9810 de Samsung en im...
- [+] 09/01: CES: Les PC Qualcomm Snapdragon 835...
- [+] 21/11: Nouvelle faille de sécurité de l'In...
- [+] 09/06: Intel fâché contre l'émulation x86 ...
- [+] 29/05: ARM annonce les Cortex-A75, A55 et ...
- [+] 27/12: Le 10nm de TSMC est bien à l'heure
- [+] 08/12: Windows 10 ARM avec Win32, la fin d...