
Les derniers contenus liés aux tags GPGPU et Tesla
Nvidia dévoile des Tesla 20 avec Fermi
Computex : serveur Tesla chez Supermicro
Computex : Nvidia mise sur GPU Computing
Nvidia détaille sa stratégie
Nvidia lance Tesla
Nvidia lance la Tesla K80: double GK210 avec Boost
Nvidia annonce la Tesla K40 et CUDA 6
GTC: Tesla passe à Kepler avec les K10 et K20
Computex: serveurs avec GPUs chez Supermicro
Tesla 20 et Fermi : plus de détails
Nvidia lance la Tesla K80: double GK210 avec Boost
Lors de l'annonce d'une nouvelle gamme de Quadro cet été, nous nous étions étonnés de ne pas voir arriver un modèle haut de gamme basé sur un nouveau "gros" GPU Kepler : le GK210. Ce dernier n'est cependant pas passé à la trappe et vient d'être introduit au travers de la nouvelle carte accélératrice Tesla K80.

Après les Tesla K10, K20, K20X et K40, Nvidia introduit le Tesla K80 qui est le second modèle bi-GPU de la famille. Elle embarque en effet deux GK210, une petite évolution des GK110/GK110B exploités sur différents segments depuis deux ans. De quoi pousser les performances un cran plus haut tout en restant sur un même format, mais bien entendu en revoyant les demandes énergétiques à la hausse.
La Tesla K80La Tesla K80 se contente de GPU partiellement fonctionnels, seules 2496 unités de calcul sur 2880 sont actives, ce qui permet de limiter quelque peu la consommation. De quoi atteindre de 5.6 à 8.7 Tflops en simple précision et de 1.9 à 2.9 Tflops en double précision. Pour le reste, le bus mémoire est complet avec 384-bit par GPU pour une bande passante totale qui atteint 480 Go/s.

Comme pour les Tesla K40, chaque GPU de la Tesla K80 profite de 12 Go de GDDR5 avec une protection ECC optionnelle qui réduit la bande passante et la quantité de mémoire réellement disponible. Elle est alors réduite de 1/16ème et passe à 11.25 Go par GPU.
Le TDP de cet accélérateur bi-GPU est de 300W, contre 235W pour les Tesla mono-GPU. Une augmentation plutôt contenue liée au fait que le GK210 est un petit peu plus efficace sur le plan énergétique mais surtout à la mise en place d'un turbo dynamique et d'une fréquence de base relativement faible.
Les Tesla précédentes profitaient déjà d'un mode turbo, dénommé GPU Boost comme sur GeForce, mais il était statique et le TDP était défini par Nvidia comme la consommation moyenne du GPU à sa fréquence de base lors de l'exécution d'un algorithme gourmand finement optimisé pour exploiter au mieux le GPU : DGEMM. Si le GPU était exploité pour faire tourner des tâches moins lourdes, ou s'il était particulièrement bien refroidi, il était possible à travers une API spécifique de faire passer manuellement le GPU à un niveau de fréquence supérieur. Par exemple le GPU de la Tesla K40 est cadencé par défaut à 745 MHz, mais il peut être configuré en mode 810 ou 875 MHz et voir sa puissance de calcul bondir de 17%.
Nvidia justifiait l'utilisation d'un turbo statique par la nécessité de proposer un niveau de performances stable et un comportement déterministe, notamment parce que certains clusters font travailler les GPU en parallèle de manière synchrone. Un autre élément était probablement que valider un turbo dynamique était plus complexe dans le monde professionnel que grand public.
Avec la Tesla K80 cela change et par défaut c'est un turbo dynamique qui est activé et qui fonctionne de la même manière que sur les GeForce récentes à ceci près que pour des raisons de sécurité, le GPU débute à sa fréquence de base et accélère progressivement si les limites de consommation (150W par GPU) et de température n'ont pas été atteintes (il part de la fréquence maximale et la réduit sur GeForce). La plage pour ce turbo dynamique est particulièrement élevée, de 562 à 875 MHz, ce qui représente jusqu'à 55% de performances supplémentaires lorsque les tâches ne sont pas très lourdes. C'est bien entendu dans ce type de cas que cette Tesla K80 se démarquera le plus d'une K40. A noter que Nvidia propose toujours, optionnellement, la sélection de manière statique d'un certain niveau de fréquence.

Il s'agit d'un format dédié au serveur et donc passif, pour cette carte de 267mm de long, qui semble reprendre le même PCB que celui de la GeForce GTX Titan Z. Petite nouveauté, la Tesla K80 n'est pas alimentée via des connecteurs PCI Express mais bien via un seul connecteur d'alimentation CPU 8 broches, plus adapté aux serveurs et qui simplifie le câblage (les traces pour ce connecteur sont présentes sur la GTX Titan Z mais il n'a pas été utilisé).
La Tesla K80 est disponible dès à présent à un tarif de 5300$ et a été validée par Cray (CS-Storm, 8 K80 par nud 2U), Dell (C4130, 4 K80 par nud 1U), HP (SL270, 8 K80 par nud 4U half-width) et Quanta (S2BV, 4 K80 par nud 1U). De quoi pousser à la hausse la densité des capacités de calcul et atteindre de 7.5 à 11.6 Tflops en double précision par U suivant la tâche.
A noter que la concurrence n'est pas pour autant larguée. AMD a implémenté une proportion plus élevée d'unités de calcul double précision dans son dernier GPU haut de gamme (Hawaii), ce qui permet à la FirePro S9150 d'afficher un débit similaire à celui de la Tesla K80 et une densité de 10.1 Tflops par U dans le même type de serveurs.
La Tesla K8En octobre Nvidia a discrètement lancé un autre membre dans la famille Tesla : la K8. Celle-ci est en fait équipée d'un GPU Kepler GK104, non-adapté au calcul en double précision. Grossièrement il s'agit de l'équivalent Tesla d'une GeForce GTX 770/680. Le design proposé par Nvidia a la particularité d'être single slot et actif mais est prévu exclusivement pour l'intégration dans un serveur et non dans une station de travail.

Le GPU, qui affiche de 1.4 à 2.5 Tflops en simple précision, est associé à 8 Go de mémoire. Par défaut, il est cadencé à 693 MHz (2.1 Tflops) et affiche un TDP de 100W. Pour les tâches légères il peut être poussé à 811 MHz et il est également possible d'activer un mode 70W dans lequel la fréquence tombe alors à 445 MHz. Par ailleurs, l'interface PCI Express de ce GPU est limitée au PCI Express 2.0 dans le monde professionnel.
GK210, quoi de neuf ?
Alors que la génération de GPU Maxwell a pris place dans le haut de gamme grand public, c'est un nouveau GPU de la famille Kepler que Nvidia vient d'introduire dans sa gamme Tesla. Nvidia ne communique que peu de détails sur les évolutions apportées par le GK210 qui reste fabriqué en 28 nanomètres et présente une configuration globale similaire à celle du GK110. Nvidia se contente de préciser que le fichier registre et la mémoire partagée ont été doublés, ce qui dans les deux cas permet de mieux alimenter les unités de calcul du GPU et donc son rendement.
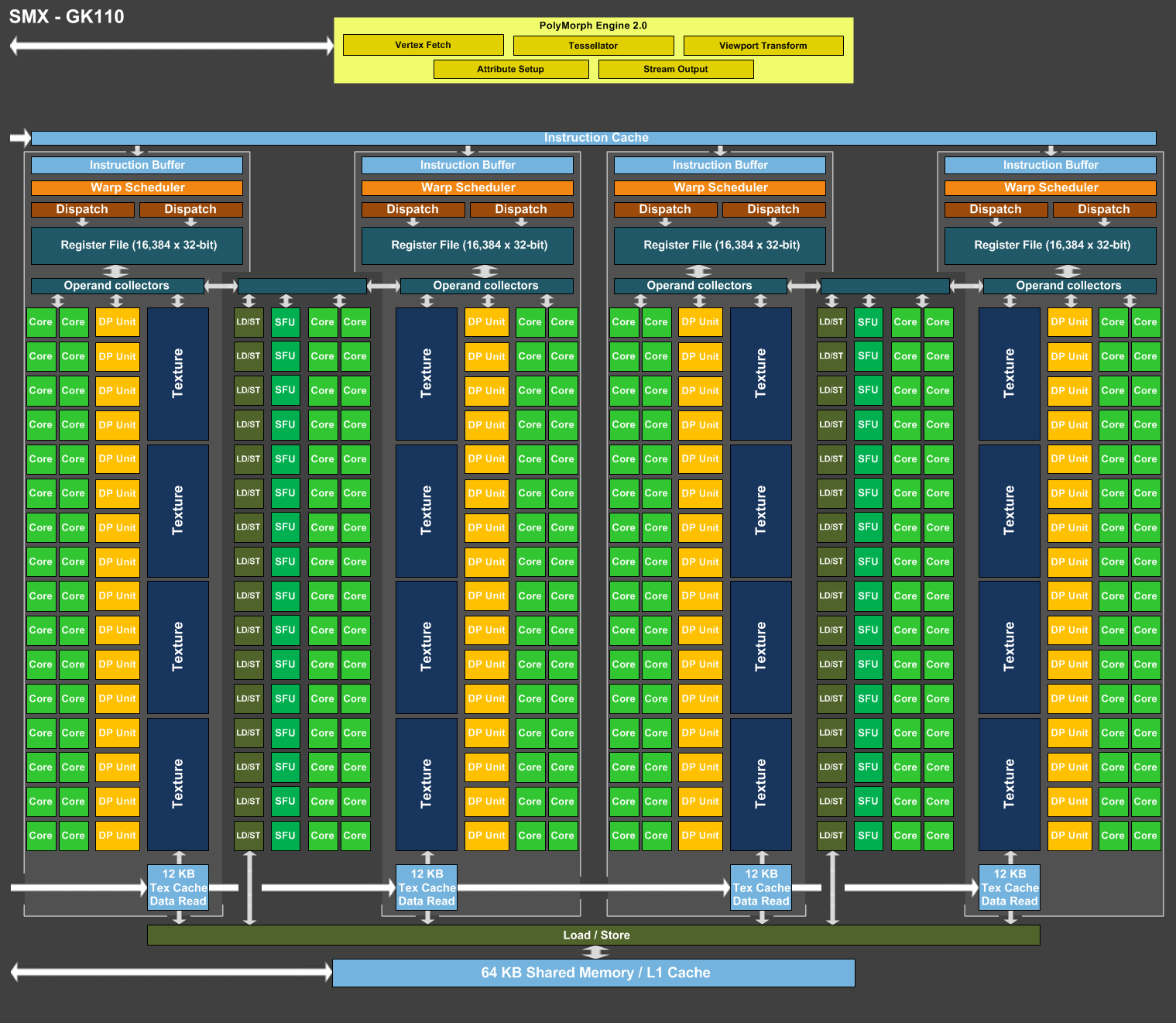
[ GK110 ] [ GK210 ]
Plus en détail, sur le GK110 comme sur tous les autres GPU Kepler, les unités de calcul sont intégrées dans les SMX, les blocs fondamentaux de l'architecture Kepler. Chaque SMX est subdivisé en 4 partitions qui se partagent l'accès aux unités de calcul, dont 192 FMA simple précision et 64 FMA double précision dans le cas des GPU GK110 et GK210. Chacune de ces partitions dispose d'un ordonnanceur et d'un fichier registres indépendant de 64 Ko, ce qui équivaut à 16384 registres 32-bit ou 8192 registres 64-bit. Le GPU étant une machine optimisée pour le débit, ces imposants fichiers registres sont exploités pour s'assurer que suffisamment d'éléments ("threads") puissent résider en interne de manière à ce que leur traitement successif puisque masquer la latence qui peut être très élevée pour certaines opérations.
Bien qu'imposants, ces fichiers registres ne sont pas sans limite et lorsqu'elle est atteinte, le taux d'utilisation des unités de calcul peut chuter fortement. Cela peut arriver quand le code à exécuter a besoin d'un nombre important de registres, quand de nombreuses opérations à latence élevée sont exécutées ou encore en 64-bit, mode deux fois plus gourmand sur ce point. Il peut ainsi s'agir d'un facteur limitant dans le cadre du calcul massivement parallèle et avec le GK210, Nvidia fait évoluer ces fichiers registres qui passent pour chaque partition de 64 Ko à 128 Ko (soit de 256 à 512 Ko par SMX et 7.5 Mo au total à l'échelle du GPU). De quoi s'assurer un taux de remplissage moyen plus élevé et donc de meilleures performances.
Le principe est le même pour le bloc qui regroupe la mémoire partagée et le cache L1. Chaque groupe d'éléments à traiter peut se voir attribuer une certaine quantité de mémoire partagée. Plus la quantité de mémoire partagée nécessaire est élevée, moins de groupes peuvent résider en même temps dans le GPU : la latence peut alors ne plus être totalement masquée ou un algorithme moins efficace, mais exigeant moins de mémoire partagée doit être utilisé, ce qui fait chuter les performances dans les deux cas.
Avec le GK210, Nvidia fait donc évoluer cette mémoire de 64 Ko à 128 Ko par SMX, mais, détail important, la totalité de la mémoire supplémentaire est attribuée à la mémoire partagée. Ainsi, alors que la répartition L1/mémoire partagée pouvait être sur GK110 de 16/48 Ko, 32/32 Ko ou 48/16 Ko, elle pourra être soit de 16/112 Ko, soit 32/96 Ko, soit de 48/80 Ko sur GK210 (suivant la quantité de L1 jugée nécessaire par le compilateur). En d'autres termes, la mémoire partagée sera en pratique de 2.33x à 5x supérieure sur ce nouveau GPU, ce qui pourra apporter un net gain de performances pour certaines tâches. Pour rappel sur les GPU Maxwell de seconde génération, la mémoire partagée n'est plus liée au L1 et est de 96 Ko.
Contrairement à ce que nous supposions au départ face à l'absence de réponse de Nvidia à cette question, le GK210 ne reprend pas la modification apportée aux autres GPU de la lignée GK2xx par rapport à la lignée GK1xx : la réduction de moitié du nombre d'unités de texturing. Un compromis qui permet de réduire la taille des SMX avec un impact sur les performances lors du rendu 3D, mais qui n'a pas été retenu dans le cas du GK210 qui conserve ses 240 unités de texturing, soit 16 par SMX. De quoi lui permettre de conserver l'ensemble de 4 petits caches de 12 Ko spécifiques aux unités de texturing (48 Ko par SMX). Ces derniers peuvent être déviés de leur rôle principal pour faire office de cache en lecture très performant.
Du côté grand public, ce GPU GK210 n'aura peut-être aucune existence et dans tous les cas un intérêt limité étant donné que les GPU de la nouvelle génération Maxwell y sont déjà commercialisés et sont plus performants et plus évolués sur le plan des fonctionnalités. Il permet par contre à Nvidia de proposer un GPU plus efficace dans le domaine du calcul massivement parallèle et pourrait bien être le premier GPU conçu spécialement pour cet usage. Dans tous les cas, Nvidia a de toute évidence stoppé la production de puces GK110B et, si nécessaire, pourra simplement remplacer le GK110/110B par un GK210 sur n'importe lequel de ses produits.
Reste que le timing de son arrivée peut évidemment sembler étrange. Pourquoi concevoir et introduire fin 2014 un nouveau GPU de l'ancienne architecture Kepler, alors que l'architecture Maxwell est déjà disponible ? Et qu'un plus gros GPU Maxwell, le GM200, est attendu ? Il peut y avoir plusieurs raisons à cela et deux d'entre elles nous paraissent les plus probables : soit le GM200 est très loin d'être prêt à être commercialisé, soit le GM200 n'est pas un GPU adapté au monde du HPC, par exemple parce qu'il ne serait pas équipé pour le calcul double précision.
Rien ne dit qu'il faille y voir une quelconque confirmation, mais cette seconde possibilité ne serait pas incompatible avec les roadmaps présentées par Nvidia. En mars 2013, la roadmap faisait état de l'évolution du rendement énergétique en double précision en passant de Kepler à Maxwell et enfin à Volta. En mars 2014, l'unité utilisée par Nvidia était cette fois du calcul en simple précision et une architecture Pascal, clairement pensée pour le monde du HPC, a été intercalée entre Maxwell et Volta. Ceci dit, il nous semble difficile d'imaginer Nvidia se contenter du GK210 en 2015, et de patienter jusqu'à l'arrivée de Pascal en 2016 pour proposer une évolution plus importante sur ce marché
Nvidia annonce la Tesla K40 et CUDA 6
La semaine passée, à l'occasion du SC13 (Supercomputing 2013), Nvidia a annoncé deux nouveautés liées au calcul haute performance : l'accélérateur Tesla K40 et la version 6 de CUDA.
Pour rappel, c'est la gamme Tesla qui a été la première à profiter du plus gros GPU de la famille Kepler, le GK110. Contrairement aux Quadro K6000 et GeForce GTX 780 Ti plus récentes, cette gamme Tesla n'accueillait cependant toujours pas de version complète du GK110, c'est-à-dire avec l'ensemble de ses unités d'exécution actives. Une configuration facilitée par l'arrivée de la révision B1 du GPU.
La Tesla K40 profite ainsi de 15 SMX, de 2880 unités de calcul FMA 32-bit et de 960 unités FMA 64-bit pour afficher une puissance de calcul en hausse de près de 10% par rapport à la Tesla K20X. Par ailleurs, comme pour le Quadro K6000, Nvidia profite de la disponibilité effective de la GDDR5 4 Gbits pour faire passer la mémoire dédiée de son accélérateur de 6 à 12 Go. Sa fréquence est par ailleurs revue à la hausse ce qui profite à la bande passante mémoire en hausse de 15%.

Si la fréquence GPU ne progresse que très peu pour la Tesla K40, c'est uniquement pour garantir que l'enveloppe thermique ne soit pas atteinte dans les tâches de type calcul, sachant que, contrairement aux GeForce, Nvidia ne propose pas de turbo pour ces cartes afin d'éviter que leurs performances soient variables. Par contre, pour la Tesla K40, Nvidia propose 2 modes avec des fréquences GPU différentes : optionnellement, il sera ainsi possible de passer le GPU de 745 à 810 ou 875 MHz. Il ne s'agit pas d'un overclocking dans le sens où ces fréquences sont validées par Nvidia, ni d'un turbo automatique, même si Nvidia place cette possibilité sous l'appellation GPU Boost, marque du turbo des GeForce... Si la personne qui exploite ces Tesla K40 constate qu'elles restent loin de leur TDP dans une certaine situation, elle aura la possibilité de passer à un de ces modes de fréquence supérieure. De quoi profiter 9% voire 17% de puissance supplémentaire.

A noter que la Tesla K40 sera proposée autant avec un refroidissement actif, comme la K20, qu'avec un refroidissement passif en vue d'intégration dans un serveur, comme la K20X. Enfin, le PCI Express 3.0 est activé sur la K40 contrairement aux K20/X.
Nvidia ne communique pas au niveau de la tarification, mais elle devrait rester inférieure à celle de la Quadro K6000, probablement passer à 5000$ alors que les K20/X devraient voir leur tarif baisser. Il faut cependant garder en tête que sur ce marché de niche, les prix sont fortement variables, les grossistes n'hésitant pas à se réserver des marges conséquentes. Ainsi pour des tarifs annoncés par Nvidia de 3200$ et de 5000$ pour les K20 et K20X, en pratique, il fallait en général compter plutôt 4000$ et 7500$, la même chose en euros.
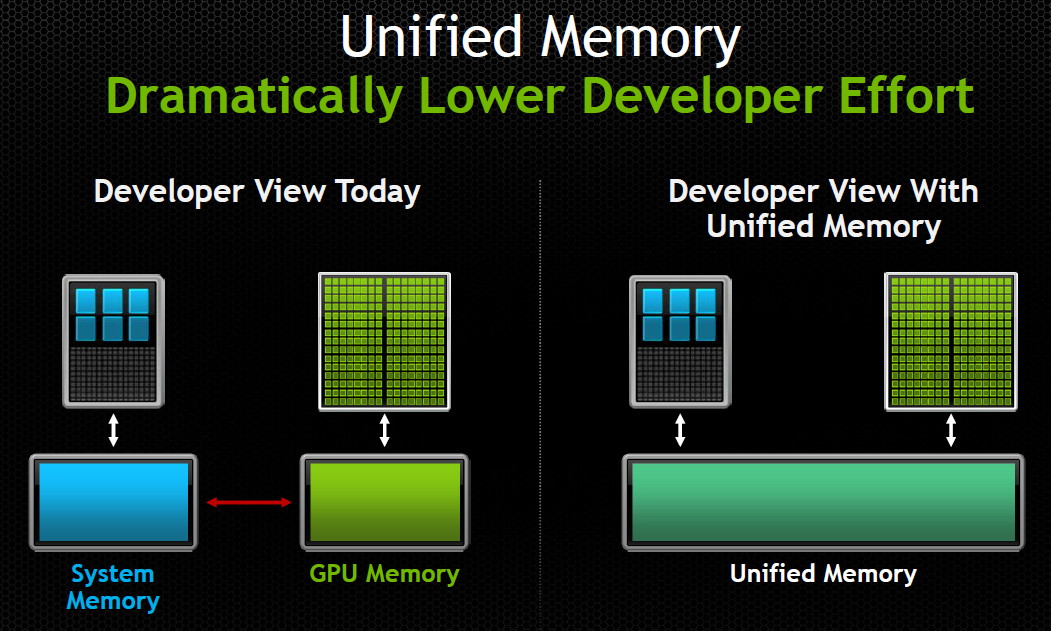
Parallèlement à l'arrivée de cette nouvelle Tesla, Nvidia a annoncé CUDA 6 qui apporte une nouveauté majeure et très attendue : la prise en charge d'une mémoire unifiée. Une fonctionnalité qui donne l'impression d'être annoncée et réannoncée régulièrement, AMD et Nvidia ayant régulièrement joué sur les mots à ce niveau. Pour rappel, depuis quelques temps, CUDA supporte un adressage de mémoire virtuelle unifié, qui facilite quelque peu le développement mais n'était qu'un premier pas. La mémoire unifiée, représente cette fois une abstraction totale de la gestion de la mémoire : il n'est plus nécessaire que le développeur gère les transferts de données de la mémoire centrale vers la mémoire de l'accélérateur.
Une gestion manuelle de la mémoire restera possible, étant donné qu'aussi bénéfique soit cette simplification, elle peut avoir un coût sur le plan des performances et de l'efficacité puisqu'il reviendra aux pilotes et/ou aux compilateurs d'essayer de placer automatiquement les données au bon endroit.

Confiant dans l'avenir, Nvidia termine par annoncer que l'ouverture par IBM, cet été, de sa plateforme serveur POWERn, va permettre d'y intégrer des accélérateurs Tesla dès 2014. Des accélérateurs qui seront ainsi exploités non plus uniquement sur x86 mais également sur architectures POWER et ARMv8.
GTC: Tesla passe à Kepler avec les K10 et K20

Nvidia vient de dévoiler deux nouvelles cartes Tesla basées sur l'architecture Kepler. La première, dénommée K10 est en quelque sorte une version Tesla serveur de la GeForce GTX 690. Il s'agit donc d'une carte équipée de 2 GPU GK104 et d'un switch PCI Express 3.0 PLX. Par rapport à la GeForce GTX 690, les fréquences ont bien entendu été revues à la baisse et passent d'une fourchette de 915 à plus de 1100 Mhz (suivant le niveau de turbo) à 745 MHz pour le GPU et de 1500 à 1250 MHz pour la mémoire.
Nvidia semble ainsi avoir laissé de côté GPU Boost, probablement parce que la variabilité qui y est liée n'est pas compatible avec le monde professionnel. La base de la technologie, qui permet de contrôler dynamiquement la fréquence pour maintenir un certain TDP est par contre de toute évidence de la partie, ce qui permet à Nvidia de proposer un TDP relativement faible qui tourne autour de 225-235W, contre 300W pour la GeForce GTX 690.
La K10 est équipée de 4 Go de mémoire GDDR5 par GPU, soit 8 Go au total, et supporte l'ECC, d'une manière similaire à ce qui se fait sur les précédentes cartes Tesla : une partie de la mémoire est utilisée pour stocker les données de parité, ce qui réduit l'espace mémoire disponible ainsi que la bande passante pratique. La puissance de calcul en double précision reste par contre extrêmement faible, tout comme certaines opérations logique ou sur les entiers, le GPU GK104 étant très limité à ce niveau. En d'autres termes, la carte K10 affiche une puissance de calcul en simple précision flottante énorme, de 4577 Gflops et sera donc destinée à ce type de calculs uniquement. En double précision le débit tombe à 190 Gflops.
La seconde carte Kepler annoncée aujourd'hui, la K20 est la plus intéressante des deux puisqu'elle embarquera un GPU GK110 au sujet duquel Nvidia vient de donner les premières informations. Peu de détails sur la K20 sont communiqués à ce jour, ses spécifications ne seront fixées que plus tard dans l'année puisqu'elle est prévue pour le dernier trimestre 2012. Il est cependant probable qu'elle soit équipée d'un GK110 partiellement castré avec 13 blocs d'unités de calcul actifs sur les 15 disponibles pour un total de 2496 de ces unités de calcul. Nvidia indique par ailleurs que ses performances en double précision seront triplées par rapport à la génération actuelle et supérieures à 1 Tflops, ce qui en fera une carte bien plus polyvalente pour le calcul, d'autant plus que son GPU apporte plusieurs innovations importantes pour faciliter son exploitation avec un maximum d'efficacité.

La carte K20 devrait être accompagnée de 6 Go de mémoire GDDR5 et sera disponible avec un TDP de 225W, ce qui est plutôt impressionnant compte tenu de la complexité de ce GPU. Il est probable que Nvidia profite du fait qu'en général les blocs du GPU dédiés au graphique ne seront pas utilisés pour pouvoir compresser le TDP. Nvidia nous précise cependant que si un intégrateur dispose d'une plateforme certifiée pour un TDP plus élevé, la carte K20 pourra s'y adapter pour profiter de la marge supplémentaire. Elle sera par ailleurs disponible en version workstation en plus de la version serveur.
Computex: serveurs avec GPUs chez Supermicro



Supermicro exposait sur le salon plusieurs systèmes optimisés pour le GPU computing tant du côté dAMD que de Nvidia. Le spécialiste du serveur explique proposer les deux solutions à ses clients mais ne pas les mettre au point directement et simplement certifier la compatibilité de ces serveurs avec certains modèles proposés par AMD et Nvidia. Cest le cas des Tesla C2050 et C2070 basées sur le GF100. Du côté dAMD ce sont des FirePro V8800 qui étaient utilisées dans les systèmes puisque les cartes FireStream équivalentes et optimisées pour le format des serveurs manquent toujours à lappel.

Interrogé sur le succès de ces solutions, Supermicro nous a indiqué quil était toujours très réduit étant donné que le GPU computing reste encore globalement à létat de recherche et développement. Les logiciels compatibles, optimisés et à létat de production sont encore rares ce qui limite grossièrement le marché aux développeurs et aux universités. Supermicro estime cependant que ce type de serveurs pourrait connaître un succès de plus en plus grand et compte donc continuer à suivre le GPU computing de près. Notre interlocuteur nous a ensuite précisé avec un grand sourire que les marges énormes sur ce type de serveur et le coût relativement réduit en développement (il nest pas nécessaire de concevoir les cartes accélératrices et la densité nest pas réellement travaillée) font que peu importe si ce marché explose réellement un jour, le simple fait dalimenter son développement est déjà très rentable.
Tesla 20 et Fermi : plus de détails
Un membre du forum de notre confère italien Hardware Upgrade est tombé sur le document BD-04983-001_v01 de Nvidia qui contient les spécifications des cartes Tesla C2050 et C2070. Un fichier type que nous avons lhabitude de parcourir pour chaque modèle mais qui en principe nest pas public et est fourni uniquement aux partenaires de Nvidia via des échanges privés ou son extranet. Il mentionne les spécifications de base des cartes ainsi que leurs propriétés physiques.
Etant donné que Nvidia essaye de maintenir le hype sur Fermi en laissant filer tantôt un détail, tantôt une photo, nous pouvons supposer que ce fichier nest pas apparu par accident. Dans sa situation, continuer à faire parler de son futur GPU est le but principal. Ceci étant dit, ce document nous apporte une information importante qui confirme ce que nous pensons depuis quelques temps.
Lors de lannonce des cartes Tesla 20, nous avions pointé du doigt la faible fréquence que la puissance de calcul avancée par Nvidia impliquait. Cétait bien entendu en supposant que toutes les unités du GPU seraient fonctionnelles, ce qui nous est par la suite apparu de moins en moins probable. Daprès les nouvelles informations, 2 cores ou partitions de 32 « cores » sur les 16 que contient le GPU seront désactivées. Les cartes Tesla C2050 et C2070 disposeront donc en réalité de 448 cores actifs cadencés entre 1.25 et 1.4 GHz.
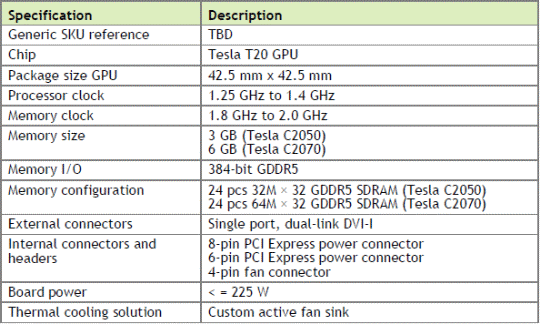
Si nous mettons en relation ces nouvelles données par rapport aux chiffres précédents, à savoir entre 520 et 630 Gflops en double précision, nous obtenons 1.16 et 1.4 GHz. La fourchette est similaire mais légèrement différente, ce qui peut sexpliquer par la date différente de lévaluation des fréquences ou par une puissance de calcul quelque peu réduite quand la protection ECC est activée. Nvidia donne également des informations sur la mémoire et parle de 1.8 à 2 GHz pour la GDDR5, ce que nous supposons correspondre à la fréquence denvoi des données, soit 900 à 1 GHz pour lenvoi des commandes, pour une bande passante de 160 à 179 Go/s.
Vous noterez par ailleurs que Nvidia ne place pas de mémoire supplémentaire pour stocker les données de parité et que le bus nest pas élargi pour la prendre en compte, comme cest le cas pour la mémoire système des serveurs. Autrement dit, lactivation de lECC va réduire la bande passante et lespace mémoire réellement disponible. Nvidia parle de 2.625 et 5.25 Go au lieu de 3 et 6 Go respectivement pour les cartes Tesla C2050 et C2070. Cela représente un coût de 1/8ème qui sera identique au niveau de la bande passante. Vous remarquerez que le coût en général de la mémoire ECC est de 1/9ème puisquun bit supplémentaire de parité est stocké pour 8 bits de données. Nous supposons que cest le même principe pour Fermi, mais qui doit par contre gérer lECC avec un bus qui nest pas élargi à 9/8ème quand cette technologie est activée. Etant donné quil utilise des contrôleurs mémoire 64 bits avec un prefetch de 8 bits, soit des accès de 512 bits, nous pouvons imaginer que lECC prend place dans cette structure. Ainsi, sur les 512 bits, 448 seraient réservés aux données, 56 pour la parité et 8 bits seraient perdus. Reste à savoir si le coût du calcul et du contrôle de la parité est important, faible ou nul, sil est traité par des unités dédiées dans le contrôleur mémoire où via les cores

Au final, nous avons donc 448 « cores », à 1.25/1.4 GHz et de la mémoire GDDR5 à 1.8/2.0 GHz. Pas très impressionnant diront certains. Sur le plan de la puissance de calcul, les Radeon HD 5870 font mieux et nont pas un gros désavantage en bande passante mémoire malgré leur bus plus petit. Mais il faut garder en tête quil sagit ici des cartes Tesla, pas des GeForce, pour lesquelles le niveau de tolérance est beaucoup plus strict et le câblage de la mémoire est rendu plus complexe puisquil faut placer le double de puces pour supporter 3 Go et 6 Go. Un élément dinquiétude légitime concerne les 2 partitions désactivées alors que nous aurions pu penser que Nvidia utiliserait les meilleurs exemplaires de Fermi, cest-à-dire complètement fonctionnels pour les cartes Tesla. Ce nest quà moitié étonnant selon nous, puisque nous avons déjà observé de grosses castrations sur les Quadro et que lintérêt de Fermi pour ce marché viendra bien plus de ses avancées architecturales et de ce quelles impliquent au niveau logiciel que de sa puissance de calcul. Passer de 16 à 14 partitions ne réduit donc pas lintérêt du produit.
Que se passera-t-il pour la version GeForce ? Tout est possible et va dépendre de la qualité de la production et des performances de Fermi par rapport à loffre actuelle dAMD. Si Nvidia peut le faire et en a besoin pour battre AMD, il est évident quune GeForce équipée dun Fermi complètement fonctionnel verra le jour. Elle pourra également profiter dune GDDR5 plus rapide et dune bande passante mémoire en hausse dau moins 20%.
Lélément le plus inquiétant dans tout cela concerne la consommation de Fermi. Les cartes Tesla C2050 et C2070 sont annoncées avec un TDP de 225 watts. Les GeForce feront léconomie de la moitié des modules mémoire, mais consommeront probablement au final plus à cause de fréquences en hausse et déventuellement 2 partitions actives en plus. La consommation risque donc dêtre un élément important dans la détermination des spécifications des GeForce Fermi.
Notez pour finir que si le consensus actuel semble être établi sur une disponibilité pour mars, nous estimons toujours de notre côté quelle devrait intervenir plus tôt, bien que probablement avec une disponibilité limitée. Selon nos informations la révision qui sera utilisée pour la production est prête et cest plutôt le côté logiciel qui doit maintenant être finalisé, sujet sur lequel certaines de nos sources se veulent rassurantes alors que dautres indiquent quil y a encore du pain sur la planche. Une chose est sûre, les développeurs de Nvidia ne vont pas prendre 2 semaines de congés pendant les fêtes comme cest le cas chez AMD !