
AMD Ryzen 7 1800X en test, le retour d'AMD ?



Si vous avez lu avec attention les pages précédentes, vous aurez remarqué que le Ryzen 7 1800X a un comportement assez différent des autres processeurs de notre comparatif.
Nous avons souhaité comprendre pourquoi et nous pensons avoir un début de réponse. Les détails qui suivent peuvent paraître complexes et nous nous en excusons, ils sont cependant nécessaires pour expliquer les comportements que nous avons notés.
Les benchmarks qui réussissent moins bien à Ryzen (on pense en particulier à 7-Zip et WinRAR, mais aussi aux jeux) ont un point commun : ils sont connus pour être assez sensibles au contrôleur mémoire et à la rapidité des caches. Nous avons donc voulu commencer par regarder la bande passante mémoire obtenue sur trois plateformes :
- Core i7 6900K
- Ryzen 7 1800X
- FX-8350
Pour obtenir un point de comparaison, le 6900K est testé dans deux configurations, avec deux et quatre canaux mémoires actifs.
Afin d'obtenir une meilleure lecture, nous cadençons ces puces 8 coeurs à 3 GHz en désactivant SMT et HT sur les plateformes qui en sont pourvues. La mémoire est réglée comme pour tous nos tests précédents, à savoir :
- DDR4-2400 15-15-15-35
- DDR3-1600 9-9-9-24
Voici les résultats obtenus. Nous utilisons une version beta de l'excellent Aida64 :

Si l'on compare les bandes passantes sur deux canaux, AMD n'a pas a rougir avec des scores au dessus d'Intel en écriture et en copie, et très proche en lecture. Les problèmes ne viennent donc pas d'ici. La latence par contre dénote, on est ici à 98 nanosecondes, soit une latence 40% plus élevée que celle du 6900K !
Il ne faut pas minimiser cet écart, +28ns est particulièrement élevé et est équivalent à fonctionner avec des timings mémoires très hauts. Pour vous donner un ordre d'idée, passer, en DDR4-2133, de timings 11-11-11 à 15-15-15 rajoute une latence de 4ns. L'impact est donc non négligeable, même s'il n'explique à notre avis qu'une partie du problème.
Une latence plus élevée seulement ?
Pour en comprendre la raison, il faut revenir à la manière dont Ryzen fonctionne. Vous vous souvenez probablement du fait que Ryzen est composé de deux CCX, les CPU Complex de quatre coeurs, qui incluent chacun leur propre segment de cache L3.
Comme nous l'avions pointé un peu plus tôt, ces coeurs ne sont pas interconnectés directement, AMD les relies à un data fabric, un système de bus interne qui va jusqu'au contrôleur mémoire double canal.
En pratique, un accès mémoire pour le processeur ne se réalise pas de manière isolée. Lorsque le processeur a besoin d'une donnée, il va commencer par interroger sa hiérarchie de caches, pour voir si la donnée, à jour, est présente. Si c'est le cas, elle va être lue directement et aucune requête mémoire ne sera effectuée. La double partition du L3 de Ryzen complique cependant les choses. Lorsqu'une donnée est nécessaire, et après avoir vérifié à l'intérieur du CCX, le core va émettre deux requêtes en simultanée, une à destination de l'autre CCX, et l'autre à destination du contrôleur mémoire. Les deux opérations ont lieu en simultanée (attendre la réponse de l'autre CCX serait beaucoup trop pénalisant), mais elles imposent un surcoût.
Les ingénieurs d'AMD nous ont confirmé qu'il faut probablement regarder de ce côté pour expliquer la latence, même si le constructeur est resté assez vague. En pratique, désactiver un CCX (et supprimer cette seconde requête) ne change en rien la latence. Logique étant donné que les requêtes sont de toute façon effectuées en parallèle.
Un cache L3... complexe
Si cela explique la latence plus élevée, et que son impact est probablement indéniable, il n'explique pas à lui tout seul les baisses de performances nettes notées dans les benchs où la mémoire joue un rôle important. Nous avons donc regardé du côté de la mémoire cache :
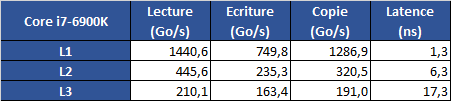
[ Core i7-6900K ] [ Ryzen 7 1800X ] [ FX-8350 ]
Faisons abstraction du FX, si ce n'est pour noter que les caches de Ryzen sont massivement plus rapide en termes de bande passante.
Si l'on compare au Core i7, on note que le L1 dispose d'une bande passante supérieure, c'est effectivement un avantage d'Intel mais qui n'explique pas les résultats que l'on obtient. La bande passante L2 est plutôt à l'avantage d'AMD, et la latence à Intel. C'est jusque là cohérent avec les données d'AMD qui annonce une latence comparable à Intel sur le L1 et un peu supérieure sur le L2.
Mais sur le L3, annoncé par AMD comme plus rapide que celui d'Intel, la latence pose question, et dans une moindre mesure la bande passante. Le L3 de Ryzen serait il plus lent que celui du FX ? Oui et non. AMD est bien conscient du problème et a ajouté dans son "Reviewer's Guide" une mention indiquant que les logiciels comme Sandra ou Aida64 ne sont pas capables de déterminer correctement la rapidité du cache L3.
Ce n'est pas la première fois que l'on rencontre une mention de ce type, même si en général les écarts sont de quelques pourcents.
Pour mesurer la bande passante, les outils doivent déterminer la taille des caches, puis effectuer des mesures sur un bloc de données. Dans certains cas, la taille des blocs à tester peut être erronée, un cache L2 mal mesuré ou mal rapporté par le processeur. Plus souvent, les méthodes d'accès agressives à la mémoire utilisées peuvent avoir un effet sur une autre partie de la puce, comme un cache TLB et réduire les performances notées. Dans ce cas, l'algorithme, ou la taille des blocs, est adaptée à la main.
AMD nous a confirmé que les auteurs de Sandra et Aida64 n'ont malheureusement pas eu accès à une plateforme Ryzen avant son lancement, les empêchant d'optimiser leurs benchmarks.
Cela ne justifiant pas l'écart, nous avons voulu réaliser un autre bench qui cette fois ci ne tente pas de déterminer magiquement la taille des blocs mémoires à tester, mais va tester de manière séquentielle différentes tailles de données. De quoi se donner une meilleure idée des performances. Voici ce que nous avons obtenus avec ce bench qui a été développé par les auteurs d'Aida64 et qui sera intégré dans une future version du logiciel.
Avant de vous donner les résultats, on se doit d'insister sur le fait que leurs auteurs n'ont pas pu le tester sur Ryzen, et que les résultats ne sont pas forcément optimaux dans certains cas (on pense aux problèmes d'algorithmes qui pourraient créer quelques petits pourcents de différence). Ces résultats sont cependant très instructifs sur le profil de performance de Ryzen :
[ Core i7-6900K ] [ Ryzen 7 1800X ] [ FX-8350 ]
Si l'on commence par regarder le cas du Core i7, les choses sont assez simples. Il dispose d'un cache L1 de 32 Ko où la latence est parfaitement alignée, d'un cache L2 de 256 Ko, on note que la latence est relativement stable jusqu'au bout, et d'un large cache L3 de 20 Mo. Jusque 16 Mo, les accès se réalisent dans le cache L3 et la latence est excellente, dès que la taille des accès augmente par contre, une partie des données est lue en mémoire centrale en plus du cache et la latence "moyenne" monte, logiquement, jusqu'à atteindre la latence de la mémoire.
Sur le FX-8350, vous pouvez retrouver la même logique avec un cache L1 de 16 Ko, un L2 de 2 Mo partagé par le module (on note la montée passé 256Ko, la latence n'est pas uniforme), et un L3 de 8 Mo à latence uniforme.
Sur Ryzen, le comportement est différent. Dans sa présentation Hot Chips, AMD notait que l'accès à différentes parties du L3 pouvait avoir une latence différente (en fonction du coeur où il est attaché) à l'intérieur d'un CCX. On peut voir un comportement de ce type sur les 4 premiers Mo, et une augmentation au delà particulièrement forte. Nous ne nous attacherons pas sur ce point sans retour des auteurs du benchmark.
Cependant la situation au-delà de 8 Mo est sans appel : sur un accès de 12 Mo (dans un L3 combiné de 16 Mo), on a une latence proche de celle que l'on obtiendrait si l'on effectuait les accès au-dessus de 8 Mo en mémoire.
Nous avons posé la question à AMD qui a confirmé cela : en pratique, dans ce cas d'école le L3 du second CCX n'est pas utilisé, Ryzen se comportant comme s'il ne disposait que de 8 Mo de L3.
Il s'agit en effet d'une particularité du benchmark utilisé : pour pouvoir mesurer correctement la latence, il est indispensable que les threads soient attachées à un coeur et n'en bougent pas. Or, vous vous en souvenez probablement, le cache L3 est un cache de type "victime", il contient les données qui sont écartées du cache L2. Et pour remplir le cache L2, il faut qu'un accès se fasse... à l'intérieur du CCX. Résultat, en bloquant notre benchmark (la latence ne se mesure que sur un thread) sur le premier coeur, l'autre CCX n'est pas sollicité, son cache ne se remplissant pas.
C'est effectivement un désavantage de l'architecture même s'il est excessivement théorique : en pratique, Windows 10 adore, on ne cesse de le dire, balader les threads des logiciels d'un coeur à l'autre.
Si AMD n'a pas pu nous donner une idée de la latence d'un accès sur le second CCX, il nous a fourni une autre donnée largement plus importante : la bande passante entre ces deux CCX : ils l'auraient mesuré en pratique à seulement 22 Go/s !
Seulement, car vous l'aurez noté, cette bande passante est non seulement plus faible que celle du L3 à l'intérieur du CCX ("au moins" 175 Go/s, un chiffre à vérifier lorsque les logiciels de mesures auront été mis à jour), mais surtout inférieure... à la bande passante mémoire !
Lors de la GDC, AMD a partagé ce schéma qui donne quelques clarifications et explique le chiffre de 22 Go/s annoncé :
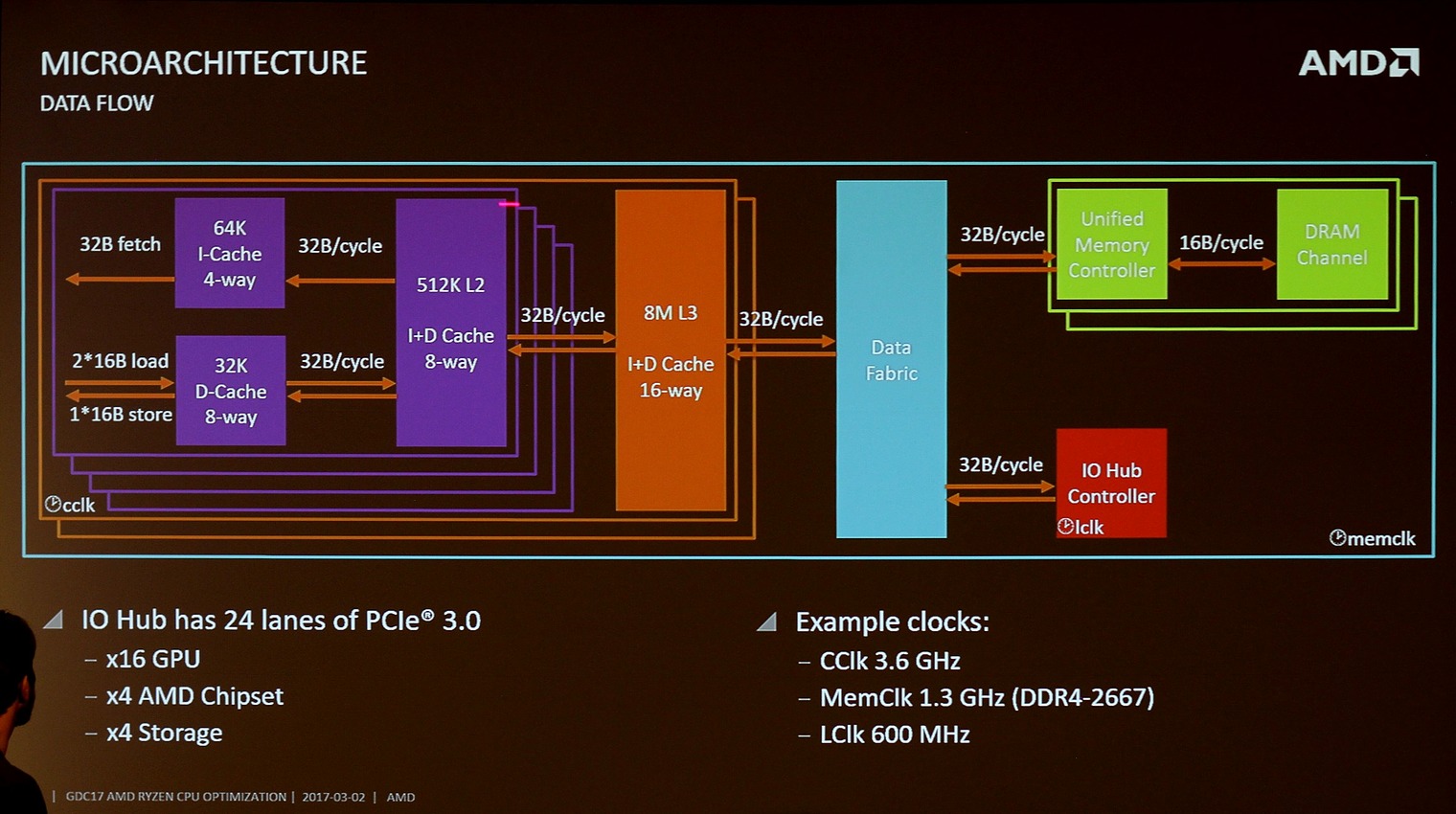
Chaque CCX est relié au Data Fabric par un bus capable de transférer 32 octets/cycles, et cadencé à la fréquence de la mémoire (1200 MHz pour de la DDR4-2400). C'est par ce bus que passent à la fois les requètes vers le contrôleur RAM, et vers l'autre CCX.
A 1200 MHz, on obtient un chiffre théorique de bande passante pour ce bus de 38 Go/s. Sachant qu'il est partagé pour les accès mémoire et RAM, on peut voir se dessiner assez rapidement des problèmes de contention entre les accès RAM, et les inter communications avec l'autre CCX. Une partie de la bande passante est elle réservée à la RAM, et l'autre aux échanges L3 ? Certaines requêtes ont elles la priorité sur d'autres ? Le constructeur n'a pas donné plus de détails pour l'instant.
On notera en prime que toutes les IO PCI Express se retrouvent aussi sur ce bus commun, ce qui peut ne pas être sans impact sur les jeux.
2 - Zen, une architecture équilibrée
3 - Ryzen, un SoC Zen 8 coeurs
4 - Ryzen 7 1800X, la gamme, DDR4
5 - Chipsets, plateforme AM4 et ASUS Crosshair VI Hero
6 - Piledriver, Zen et Broadwell-E à 3 GHz
7 - Impact du SMT/HT
8 - Retour sur le SMT et mode High Performance
9 - Overclocking en pratique
10 - Consommation, efficacité énergétique et "TDP"
11 - Protocole de test
12 - Compression : 7-Zip et WinRAR
13 - Compilation : Visual Studio et MinGW-w64/GCC
15 - IA d'échecs : Stockfish et Komodo
16 - Traitement photos : Lightroom et DxO Optics Pro
17 - Rendu 3D : Mental Ray et V-Ray
18 - Jeux 3D : Project Cars et F1 2016
19 - Jeux 3D : Civilization VI et Total War : Warhammer
20 - Jeux 3D : GTA V et Watch Dogs 2
21 - Jeux 3D : Battlefield 1 et The Witcher 3
22 - Indices de performance
23 - Retour sur le sous-système mémoire
24 - Retour sur le sous-système mémoire, suite
25 - Conclusion
Contenus relatifs
- [+] 09/05: AMD Ryzen 7 2700, Ryzen 5 2600 et I...
- [+] 23/04: MAJ de notre test des Ryzen 7 2700X...
- [+] 19/04: AMD Ryzen 2700X et 2600X : Les même...
- [+] 13/04: Les AMD Ryzen Pinnacle Ridge en pré...
- [+] 14/03: Des failles de sécurité spécifiques...
- [+] 08/03: Quatre Ryzen+ Pinnacle Ridge pour a...
- [+] 21/02: AMD Ryzen 5 2400G et Ryzen 3 2200G ...
- [+] 12/02: AMD lance les APU Ryzen 5 2400G et ...
- [+] 09/02: AMD Ryzen 3 2200G et 5 2400G : MAJ ...
- [+] 07/02: Windows 10, Meltdown et Spectre : q...