
AMD Radeon R9 285 : Tonga, la Sapphire Dual-X OC et la XFX Black Edition en test
Publié le 02/09/2014 (Mise à jour le 04/09/2014) par Damien Triolet



Tonga : 5 milliards de transistorsContrairement à ce que nous supposions dans un premier temps, Tonga n'est pas une version économique de Tahiti. Certes, AMD a fait un gros compromis sur ses spécifications, en réduisant son bus mémoire de 384 à 256 bits, mais l'intégration de toutes les nouvelles fonctionnalités récupère tout l'espace dégagé, voire en demande un peu plus !

Le GPU Tonga accompagné des 8 puces de GDDR5 qui forment son bus 256-bit.
Alors que Tahiti est annoncé avec 4.3 milliards de transistors, qui occupent une surface de 352 mm², Tonga passe à 5.0 milliards de transistors pour 368 mm², selon nos mesures. Vous noterez au passage que la densité de transistors progresse quelque peu, ce qui est probablement lié à l'utilisation de contrôleurs mémoires plus denses, comme sur Hawaii (6.2 milliards de transistors et 438 mm²).
Tonga est bien évidemment toujours fabriqué en 28 nm. Il existe par contre une interrogation quant à la variante exacte du process qui est utilisée. Synapse Design, qui fournit différents services autour de la conception de puces, et qui compte AMD parmi ses clients, a dévoilé dans une présentation que l'un de ses clients avait développé 2 GPU en 28 nm HPM, l'un de plus de 350 mm² et l'autre de plus de 500 mm². Le HPM est la variante la plus avancée du 28 nm de TSMC. Tonga pourrait peut-être correspondre à l'un de ces GPU, mais si c'est le cas, au vu de sa prestation d'aujourd'hui, il est difficile d'y trouver un avantage.
Voici un résumé des caractéristiques de tous les GPU de la famille GCN :
Oland : GCN 1.0, 6 CU, 1 triangle par cycle, 8 ROP, L2 256 Ko, 128 bits
Cape Verde : GCN 1.0, 10 CU, 1 triangle par cycle, 16 ROP, L2 512 Ko, 128 bits
Bonaire : GCN 1.1, 14 CU, 2 triangles par cycle, 16 ROP, L2 512 Ko, 128 bits
Pitcairn : GCN 1.0, 20 CU, 2 triangles par cycle, 32 ROP, L2 512 Ko, 256 bits
Tonga : GCN 1.2, 28 CU (ou plus ?), 4 triangles par cycle, 32 ROP, L2 512 Ko (ou plus ?), 256 bits
Tahiti : GCN 1.0, 32 CU, 2 triangles par cycle, 32 ROP, L2 768 Ko, 384 bits
Hawaii : GCN 1.1, 44 CU, 4 triangles par cycle, 64 ROP, L2 1024 Ko, 512 bits
Et en image pour les plus gros d'entre eux (dans le cas de Tonga nous avons représenté la possibilité qu'il intègre physiquement 28 CU ou 32 CU) :
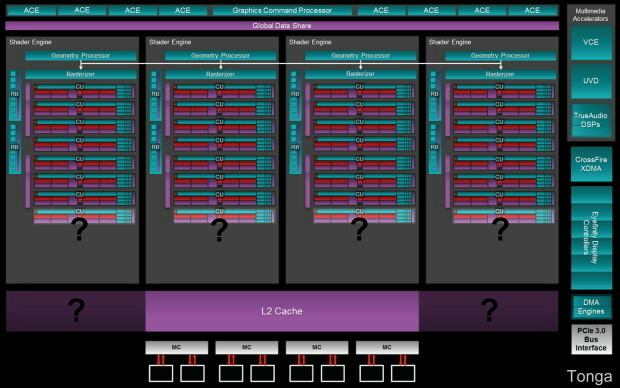
[ Bonaire ] [ Pitcairn ] [ Tahiti ] [ Tonga ] [ Hawaii ]
Pour les versions plus grandes de ces diagrammes :
Vous remarquerez plusieurs points d'interrogations concernant Tonga. Le principal étant le nombre de blocs d'unités de calcul, appelés Compute Units ou CU, présents physiquement sur la puce. 28 CU sont actifs sur la version de Tonga exploitée pour la Radeon R9 285, mais il est possible qu'AMD en ait intégré au moins 32 de manière à pouvoir proposer une Radeon R9 285X d'ici quelques temps. Par ailleurs, nous ne savons pas quelle est la taille du cache L2 de Tonga. Elle est de minimum 512 Ko mais probablement plus élevée comme c'est de plus en plus le cas sur les nouveaux GPU : 1 ou 2 Mo.
Par rapport à Tahiti, Tonga voit certes son bus mémoire amputé, mais AMD a mis en place des mécanismes pour en réduire l'impact et a doublé le nombre de processeurs géométriques chargés de la prise en charge des primitives, de leur découpe en pixels et de la tessellation.
Tonga : GCN 1.2Officiellement, AMD ne différencie pas les différentes itérations de son architecture GCN. Il y a du GCN, du GCN un peu vieux et du GCN un peu nouveau. Pas très pratique pour s'y retrouver Même s'il ne s'agit pas d'une forme sous laquelle communique AMD, nous préférons de notre côté parler de GCN 1.0 pour les premiers GPU de la famille, de GCN 1.1 pour Hawaii et Bonaire et de GCN 1.2 pour Tonga.

AMD donne très peu de détails sur les nouveautés. Il est tout d'abord question d'une amélioration des performances en tessellation, un argument qui semble devenu obligatoire dans toutes les présentations de GPU. De notre côté nous n'avons pas remarqué d'évolution marquante en dehors du gain lié au passage de 2 à 4 processeurs géométriques.
Ensuite, pour faire face à la réduction de la bande passante mémoire, AMD a mis en place de nouveaux algorithmes de compression sans perte du framebuffer. Plus spécifiquement, il s'agit de codage différentiel pour les couleurs, également appelé compression delta. Le principe de base consiste à ne pas enregistrer directement la couleur mais sa différence par rapport à une autre. Ce n'est bien entendu utile que quand l'écart entre deux couleurs est suffisamment faible, de manière à ce que cette information représente moins de bits que la couleur en elle-même. Il existe plusieurs approches de ce type mais AMD n'a pas encore répondu à nos questions concernant les détails de son implémentation. Ce support a dû être intégré au niveau des ROP mais également au niveau des unités de texturing qui doivent être capables de lire ces données compressées.
AMD parle d'un gain d'efficacité de 40% mais se base pour cela sur la mise en relation des performances de Radeon R9 280 et 285 dans 3DMark Fire Strike par rapport à leur bande passante respective. Un exemple pour le moins boiteux puisque ce benchmark est peu dépendant de la bande passante mémoire. Cependant, au vu des résultats qui vont suivre, force est de constater qu'AMD arrive réellement à compenser le passage d'un bus 384 à 256-bit. Les éléments qui y participent sont cependant divers : ce nouveau type de compression, mais également une fréquence mémoire en hausse et probablement un cache L2 plus important et d'autres petites améliorations secondaires.
Avec GCN 1.2, AMD a mis à jour le jeu d'instruction du GPU. Il est question de nouvelles instructions 16-bit, autant en entier qu'en flottants. Une précision moindre qui permet potentiellement des gains d'énergie, suivant son implémentation. La précision 16-bit est avant tout exploitée dans le monde mobile mais elle pourrait également permettre de rendre plus efficaces certains algorithmes de traitement vidéo. D'autres instructions ont été ajoutées, dédiées aux échanges de données entre threads, pour réduire les accès à la mémoire partagée, ce que Nvidia fait également sur ses derniers GPU.
De notre côté, en observant le code compilé, nous avons pu remarquer que le support de quelques instructions semble avoir été supprimé (les fmac sont par exemple remplacés par des fmad), probablement parce qu'elles ne sont plus très utiles. Le code compilé est dans bien des cas constitué de légèrement moins d'instructions, ce qui peut potentiellement le rendre plus performant sur Tonga.
Nous mettrons à jour cette section si nous obtenons des réponses à nos questions concernant ces nouveautés.


Enfin, AMD a revu toute la partie video. Tout d'abord avec un scaler de meilleure qualité, ensuite avec des mises à jour de ses moteurs d'encodage et de décodage.
Sommaire
1 - Introduction
2 - Tonga : GCN 1.2, 256-bit, 5 milliards de transistors
3 - Performances théoriques : pixels
4 - Performances théoriques : géométrie
5 - Spécifications, PowerTune
6 - Sapphire Radeon R9 285 Dual-X OC
7 - XFX Radeon R9 285 Black Edition
8 - Consommation, efficacité énergétique
9 - Bruit, températures, thermographie
10 - Protocole de test
11 - Benchmark : 3DMark et Unigine
12 - Benchmark : Anno 2070
13 - Benchmark : Batman Arkham Origins
2 - Tonga : GCN 1.2, 256-bit, 5 milliards de transistors
3 - Performances théoriques : pixels
4 - Performances théoriques : géométrie
5 - Spécifications, PowerTune
6 - Sapphire Radeon R9 285 Dual-X OC
7 - XFX Radeon R9 285 Black Edition
8 - Consommation, efficacité énergétique
9 - Bruit, températures, thermographie
10 - Protocole de test
11 - Benchmark : 3DMark et Unigine
12 - Benchmark : Anno 2070
13 - Benchmark : Batman Arkham Origins
14 - Benchmark : Battlefield 4
15 - Benchmark : Crysis 3
16 - Benchmark : Far Cry 3
17 - Benchmark : GRID 2
18 - Benchmark : Hitman Absolution
19 - Benchmark : Metro Last Light
20 - Benchmark : Splinter Cell Blacklist
21 - Benchmark : Tomb Raider
22 - Récapitulatif des performances
23 - Overclocking et cartes Sapphire / XFX
24 - Tonga vs Tahiti
25 - Conclusion
15 - Benchmark : Crysis 3
16 - Benchmark : Far Cry 3
17 - Benchmark : GRID 2
18 - Benchmark : Hitman Absolution
19 - Benchmark : Metro Last Light
20 - Benchmark : Splinter Cell Blacklist
21 - Benchmark : Tomb Raider
22 - Récapitulatif des performances
23 - Overclocking et cartes Sapphire / XFX
24 - Tonga vs Tahiti
25 - Conclusion
Vos réactions
Contenus relatifs
- [+] 04/12: Tonga a bien un bus 384-bit
- [+] 30/11: AMD Radeon R9 380X : les cartes Asu...
- [+] 19/11: AMD lance la Radeon R9 380X
- [+] 18/06: AMD lance les Radeon R300 : vaste r...
- [+] 01/06: DiRT Rally offert avec les Radeon R...
- [+] 29/04: Promotion sur les R9 285
- [+] 04/09: AMD Radeon R9 285 : Tonga, la Sapph...
- [+] 02/09: Never Settle passe en Space Edition
- [+] 26/08: R9 285 compacte chez Sapphire
- [+] 23/08: AMD annonce la Radeon R9 285 et fêt...