
AMD A10-5800K/5700 et A8-5600K/5500 : APU desktop, deuxième !
Publié le 02/10/2012 (Mise à jour le 08/01/2013) par Guillaume Louel



La première génération d'APU Llano était la (longue) concrétisation de la stratégie de Fusion qu'avait évoqué AMD en rachetant le constructeur graphique ATI : intégrer le GPU au sein des processeurs. La vision avait été plusieurs fois repoussée pour maintes raisons, et finalement réalisée par Intel début 2011 avec les Sandy Bridge, les premières puces de cette catégorie à intégrer dans leur die un cur graphique.
Fabriqué en 32nm par GlobalFoundries, Llano repose sur l'intégration de curs x86 issus de l'architecture K10.5, à savoir l'architecture utilisée par les Phenom II et les Athlon II. Deux concessions (fortes) avaient cependant été effectuées côté cache : le cache de niveau 2 limité à 1 Mo par coeur, et de l'autre, le cache L3 tout simplement absent.
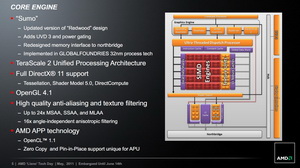

Côté GPU, Llano reposait sur l'intégration d'un GPU "Redwood", plus connu sous le nom du GPU qui animait les Radeon HD 5570. Il utilisait l'architecture VLIW5 d'AMD. Un mode Turbo était disponible pour la partie CPU sur ces puces, mais pas pour la partie GPU.
Derrière le nom de code Virgo se cache en réalité la version Desktop de Trinity (voir notre test de la version mobile). Comme nous l'avions décrit à l'époque, Trinity peut laisser penser qu'AMD est reparti d'une page blanche tant Llano et Trinity/Virgo n'ont rien en commun.

Ou presque. Il y a tout de même quelques points communs, Llano et Trinity sont par exemple tous deux des APU gravés en 32nm SOI par GlobalFoundries. Autre point commun, les deux puces sont dépourvues de cache de niveau 3. Le die de Virgo mesure 246mm2 pour un total annoncé de 1.3 milliards de transistors.
Côté CPU, exit les curs x86 K10.5 qui laissent leur place à des modules "Piledriver". Il s'agit pour rappel de la version 2 de l'architecture Bulldozer, lancée côté desktop avec les AMD FX l'année dernière. Le concept de base de Bulldozer et de Trinity repose sur la fusion de deux curs en un module qui partagent un certain nombre de ressources. Ainsi, le module dispose de deux unités de calcul pour les nombres entier, et d'une unité partagée qui sera utilisée pour les calculs en virgule flottante. Et si chaque cur dispose d'un cache de niveau 1, ils se partageront un cache de niveau 2 (plus gros, 2 Mo par module contre 1 Mo par cur pour Llano), ainsi que d'autres ressources (décodeurs d'instructions, prefetcher, etc ).

AMD annonce de très nombreux changements dans son architecture Piledriver par rapport à Bulldozer, ou plus exactement des petites corrections un peu partout. Les détails fournis par AMD restent cependant relativement de haut niveau. D'abord côté jeu d'instruction on notera que Piledriver gère les FMA3 (Fused Multiply/Add sur 3 opérandes, a = a * b +c ) en plus du FMA4 (a = b * c + d) déjà géré précédemment (Intel utilisera le FMA3 à compter de l'année prochaine, voir cette actualité pour plus de détails), ainsi que les instructions de conversion flottantes 16/32 bits F16C introduites par Intel dans Ivy Bridge.
Pour le reste les modifications se font par petites touches à tous les niveaux, les mécanismes de prédictions de branchement sont annoncés comme plus efficaces tout comme les schedulers tandis que des gains sont annoncés sur les divisions. Il est globalement assez difficile de juger l'impact qu'auront ces changements sur les performances et l'absence de cache de niveau 3 nous empêche de réaliser une comparaison à fréquence égale avec les AMD FX "Bulldozer" (il faudra attendre les AMD FX "Piledriver" Desktop, les Vishera qui devraient débarquer avant la fin du mois). AMD annonçait pour rappel un gain entre Bulldozer et Piledriver inférieur à 10%. Globalement c'est surtout du côté de la consommation et de l'efficacité énergétique qu'AMD estime avoir fait le plus de gains avec de 10 à 20% d'économie d'énergie par rapport à l'architecture Bulldozer.
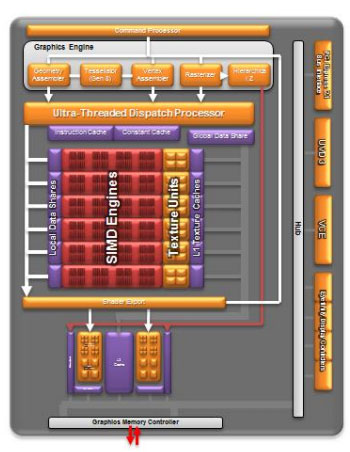
En ce qui concerne le GPU, là aussi tout est nouveau puisque l'on passe d'une architecture VLIW5 à l'architecture VLIW4 utilisée sur les GPU Cayman (Radeon HD 6900) d'AMD l'année dernière. Le nombre d'unités de calcul dépend des modèles, ainsi l'A10-5800K que nous avons testé aujourd'hui dispose de 384 unités shaders, l'A8-5600K de 256, et les A6 et A4 respectivement de 192 et 128 unités.
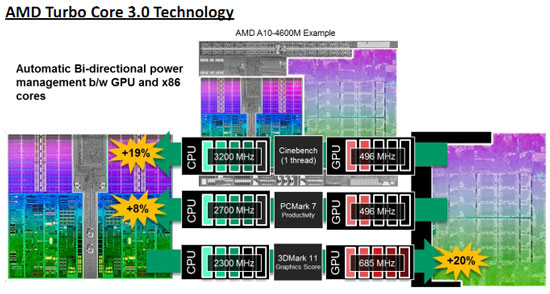
Dernière modification notable, celle du Turbo. AMD dispose désormais à la fois d'un Turbo CPU et GPU, les deux pouvant être utilisés en fonction des besoins.
 Introduction
La gamme, Gigabyte F2A85X-UP4
Introduction
La gamme, Gigabyte F2A85X-UP4

Fabriqué en 32nm par GlobalFoundries, Llano repose sur l'intégration de curs x86 issus de l'architecture K10.5, à savoir l'architecture utilisée par les Phenom II et les Athlon II. Deux concessions (fortes) avaient cependant été effectuées côté cache : le cache de niveau 2 limité à 1 Mo par coeur, et de l'autre, le cache L3 tout simplement absent.
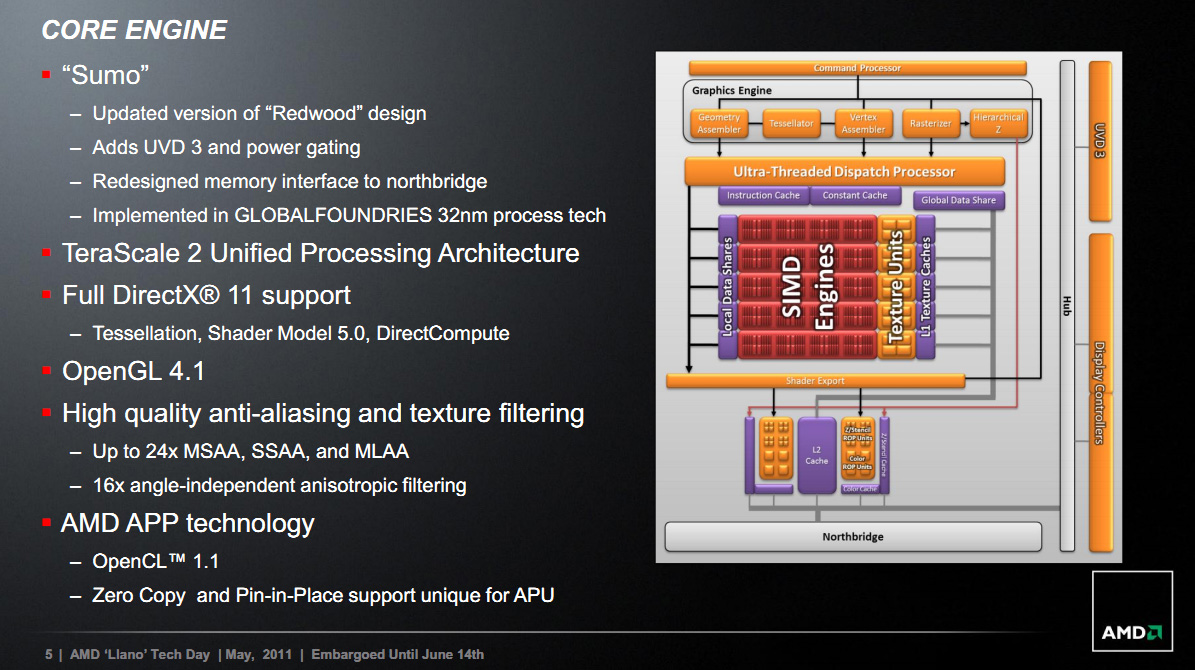

Côté GPU, Llano reposait sur l'intégration d'un GPU "Redwood", plus connu sous le nom du GPU qui animait les Radeon HD 5570. Il utilisait l'architecture VLIW5 d'AMD. Un mode Turbo était disponible pour la partie CPU sur ces puces, mais pas pour la partie GPU.
Trinity Desktop = Virgo !
Derrière le nom de code Virgo se cache en réalité la version Desktop de Trinity (voir notre test de la version mobile). Comme nous l'avions décrit à l'époque, Trinity peut laisser penser qu'AMD est reparti d'une page blanche tant Llano et Trinity/Virgo n'ont rien en commun.
Ou presque. Il y a tout de même quelques points communs, Llano et Trinity sont par exemple tous deux des APU gravés en 32nm SOI par GlobalFoundries. Autre point commun, les deux puces sont dépourvues de cache de niveau 3. Le die de Virgo mesure 246mm2 pour un total annoncé de 1.3 milliards de transistors.
Côté CPU, exit les curs x86 K10.5 qui laissent leur place à des modules "Piledriver". Il s'agit pour rappel de la version 2 de l'architecture Bulldozer, lancée côté desktop avec les AMD FX l'année dernière. Le concept de base de Bulldozer et de Trinity repose sur la fusion de deux curs en un module qui partagent un certain nombre de ressources. Ainsi, le module dispose de deux unités de calcul pour les nombres entier, et d'une unité partagée qui sera utilisée pour les calculs en virgule flottante. Et si chaque cur dispose d'un cache de niveau 1, ils se partageront un cache de niveau 2 (plus gros, 2 Mo par module contre 1 Mo par cur pour Llano), ainsi que d'autres ressources (décodeurs d'instructions, prefetcher, etc ).
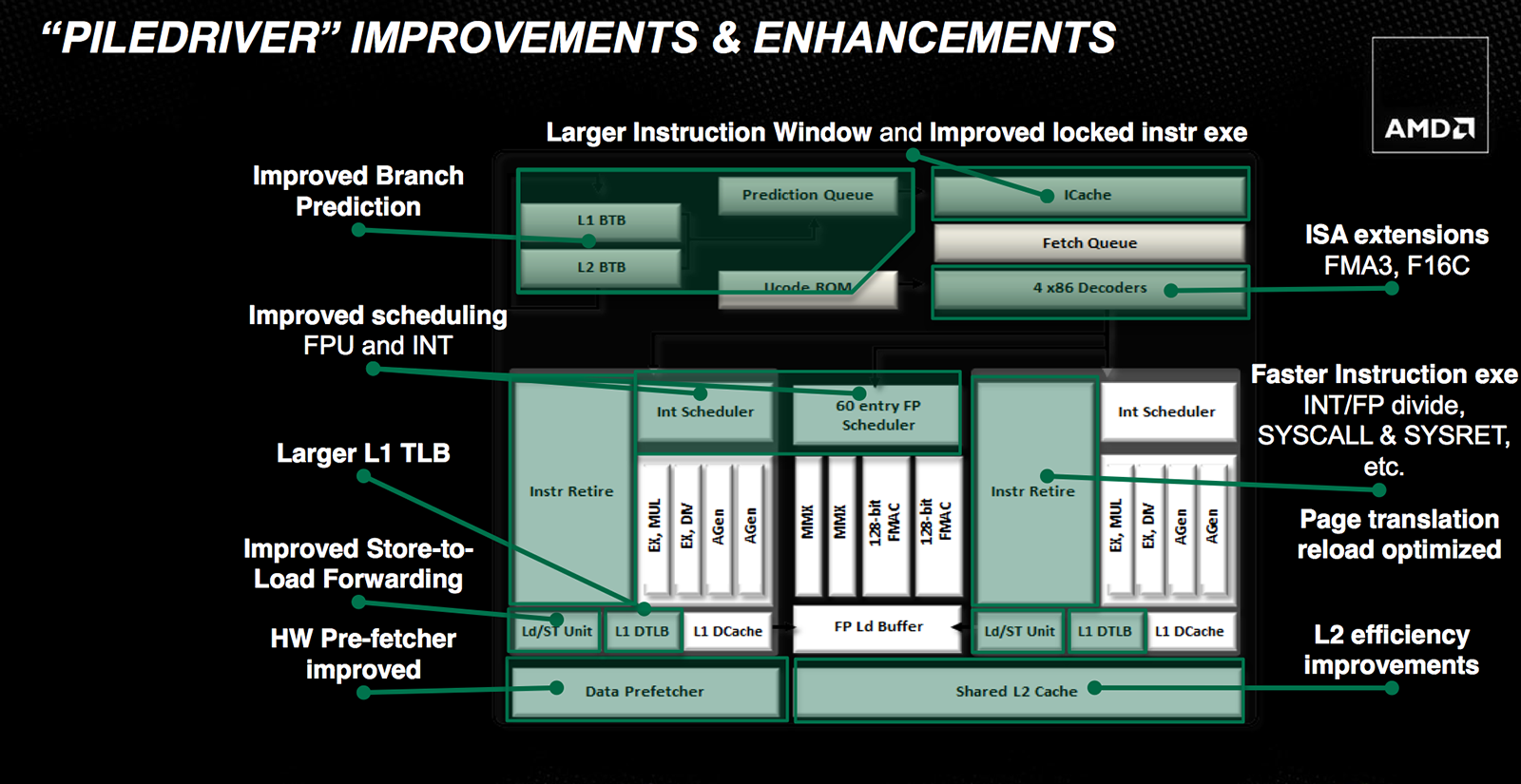
AMD annonce de très nombreux changements dans son architecture Piledriver par rapport à Bulldozer, ou plus exactement des petites corrections un peu partout. Les détails fournis par AMD restent cependant relativement de haut niveau. D'abord côté jeu d'instruction on notera que Piledriver gère les FMA3 (Fused Multiply/Add sur 3 opérandes, a = a * b +c ) en plus du FMA4 (a = b * c + d) déjà géré précédemment (Intel utilisera le FMA3 à compter de l'année prochaine, voir cette actualité pour plus de détails), ainsi que les instructions de conversion flottantes 16/32 bits F16C introduites par Intel dans Ivy Bridge.
Pour le reste les modifications se font par petites touches à tous les niveaux, les mécanismes de prédictions de branchement sont annoncés comme plus efficaces tout comme les schedulers tandis que des gains sont annoncés sur les divisions. Il est globalement assez difficile de juger l'impact qu'auront ces changements sur les performances et l'absence de cache de niveau 3 nous empêche de réaliser une comparaison à fréquence égale avec les AMD FX "Bulldozer" (il faudra attendre les AMD FX "Piledriver" Desktop, les Vishera qui devraient débarquer avant la fin du mois). AMD annonçait pour rappel un gain entre Bulldozer et Piledriver inférieur à 10%. Globalement c'est surtout du côté de la consommation et de l'efficacité énergétique qu'AMD estime avoir fait le plus de gains avec de 10 à 20% d'économie d'énergie par rapport à l'architecture Bulldozer.
En ce qui concerne le GPU, là aussi tout est nouveau puisque l'on passe d'une architecture VLIW5 à l'architecture VLIW4 utilisée sur les GPU Cayman (Radeon HD 6900) d'AMD l'année dernière. Le nombre d'unités de calcul dépend des modèles, ainsi l'A10-5800K que nous avons testé aujourd'hui dispose de 384 unités shaders, l'A8-5600K de 256, et les A6 et A4 respectivement de 192 et 128 unités.

Dernière modification notable, celle du Turbo. AMD dispose désormais à la fois d'un Turbo CPU et GPU, les deux pouvant être utilisés en fonction des besoins.
Sommaire
Vos réactions
Contenus relatifs
- [+] 17/03: AMD baisse ses prix AM3+/FM2+
- [+] 06/04: AMD pré-annonce Bristol Ridge
- [+] 13/05: AMD baisse les prix des Kaveri
- [+] 23/10: Baisse de prix des APU AMD FM2+ et ...
- [+] 04/06: Computex: AMD lance les Kaveri mobi...
- [+] 17/03: L'AMD A8-7600 se fait attendre
- [+] 21/02: mini-ITX en FM2+ pour MSI
- [+] 30/01: APU AMD A8-7600 en test, cTDP, Turb...
- [+] 14/01: Kaveri : AMD A10-7850K et A10-7700K...
- [+] 07/01: CES: AMD en dit plus sur les APU A1...